




This post will go over some ways that we here at Solve use large geospatial datasets and make them internally available for any project.
TL;DR
We show a means of extracting information for an area of interest from an overwhelmingly large raster in a matter of seconds. Please read on if you want the details.
Introduction to the data
Landsat8
Landsat8 is the most recently launched Landsat satellite, completing one Earth orbit every 99 minutes. Landsat8 data is delivered in 185km x 180km scenes, and the satellite acquires about 740 scenes every day. Data from two instruments is publicly available:
- Operational Land Imager (OLI) has nine spectral bands including visible light, near-infrared and short-wave-infrared frequencies
- Thermal Infrared Sensor (TIRS) has two thermal IR spectral bands Data is made available via a range of means.
_Satellite.jpg){kind=link}
Barest-earth model
In the context of mineral exploration, the most informative remote sensing multispectral dataset is generally one that is least influenced by vegetation, resulting in data that is primarily driven by reflection and absorption of radiation by soil and rock. Siegal and Goetz (1977) describe how even 10% vegetation cover can reduce the ability to correctly identify mineral spectra.
The Australian National University and Geoscience Australia have created Australian continental-scale mosaics of Landsat data with a 25m resolution, that attempt to minimise the influence of vegetation (Roberts et. al 2019). Please read the paper for technical details on the processes and analysis of the results. Roberts et. al (2009) also incorporate data from earlier Landsat missions into the mosaics to obtain a better barest-earth spectral model of the continent.
The essence of the process is stacking of spatially coincident data across the 30+ year the Landsat missions, applying required corrections, then using geometric median statistics on the six spectral bands used. These statistics were weighted by a series of regressions models that were built over areas of known vegetation levels. Applying the weighted geometric median to the continental-scale data results in a model of the spectra in the Landsat data that is least influenced by vegetation. From Roberts et. al, we see the barest-earth model on the left, and its inverse (most vegetated) on the right:

How we use it
Data products like the barest-earth Landsat mosaic are commonly used here at Solve in a range of machine learning applications, from prospectivity analysis to classification modelling including identification of possible errors in geological mapping.
Our own Tom Ostersen's recent demonstration:
Lithological mapping of iron-bearing units in the Pilbara:
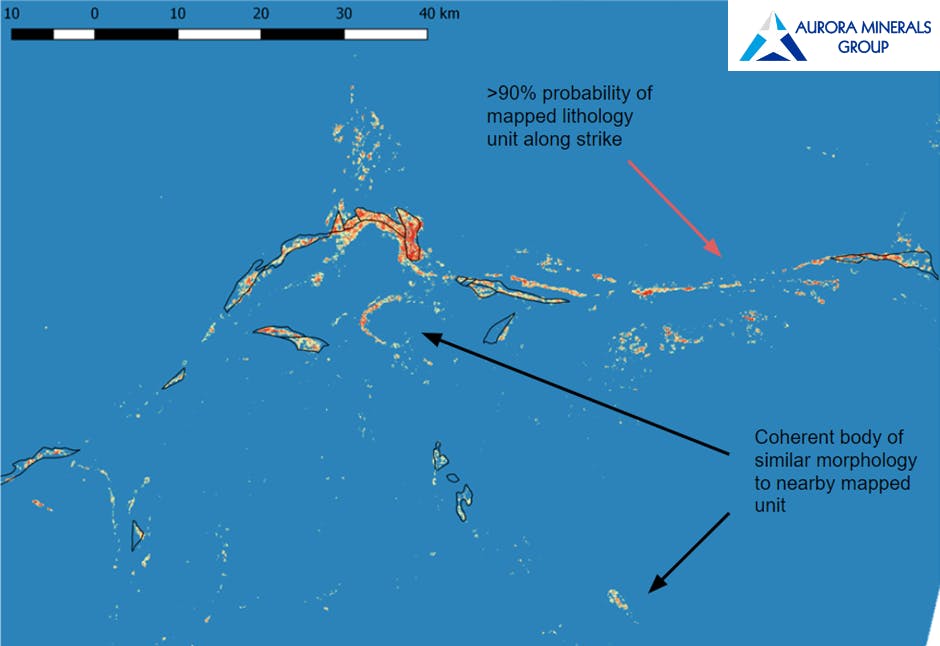
Typically, these products are used in conjunction with raw and modelled geophysics, geochemical, lithological, structural, and other available data to build as complete of a data model of an area of interest as possible. This data then informs a model that addresses our clients’ requirements.
Data availability
Geoscience Australia host the continental-scale Landsat mosaics and they are available via the National Map initiative. This is a good utility for quickly visualising many publicly available raw and curated datasets. The map allows export of the data at the resolution that is viewed on the interface, not the full resolution of the data for the viewed area.
Alternatively, Geoscience Australia allow access to their public AWS S3 bucket, where the data is split into approximately 100km x 100km tiles, and where each band is stored as a separate single-band geotiff. An example of the data as stored on the GA public data S3 bucket:
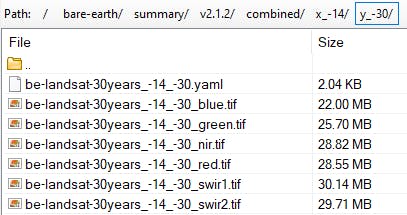
Our data requirements
Our projects that benefit from these sorts of data mosaics vary greatly in overall location and footprint, from continental-scale spectral-based mineralogy models to camp-scale soil studies. In either case, we generally prefer to work with full-resolution data, leaving the option to down-sample data at a later stage, if required.
Additionally, as usual, the turn-around time of our projects is often required to be fairly fast – waiting on data servers to provide data exports can be prohibitively slow.
Another requirement is that data served into the modelling pipeline is numeric – not rendered images. We have previously discussed how we serve up static web maps which are great for visualisation, but not for data modelling.
In summary, our requirements are full resolution, numeric data with minimal turnaround time.
The decision
The relatively recent adoption of the Cloud Optimised Geotiff (COG) standard by many - including GDAL, QGIS and Google Earth Engine - means that there are robust ways to take advantage of efficient querying of raster objects that are cloud-hosted.
![]()
One of the processes of cloud-optimisation of the geotiff is the creation of an internal tiles structure. We can then utilise this smart organisation of data and only Get request the bytes of data associated with tiles that encompass the area of interest, instead of having to download the whole geotiff.
We decided to create a COG of the Landsat 30+ year mosaic and host it on AWS S3 storage. We then designed the workflows to extract the data for an area of interest using a Python notebook.
Not stopping there, we have also implemented an AWS Lambda function that is triggered by events on an S3 bucket. This provides a zero-code solution where we drop a shape file onto S3 and receive the clipped mosaic within a matter of seconds.
The process
Creating the COG
The first step is to create the Cloud Optimised Geotiff. This requires joining the individual tiffs that represent each band of spectral data, for all the approximately 100km x 100km tiles across the extent of the data product (continental Australia). There are 1,159 tiles, each with six bands; red, green, blue, NIR, SWIR1 and SWIR2, with a total size of 142GB.
An AWS EC2 instance was started (M5.8xlarge, 128GB RAM and 32vCPU) and a 600GB EBS volume was attached. Connection to the machine was with the Visual Studio Code Remote SSH plugin.
GDAL (a translator library for raster and vector geospatial data formats) was installed, along with the GDAL Python libraries. From here:
# install gdal
sudo add-apt-repository ppa:ubuntugis/ppa && sudo apt-get update
sudo apt-get update
sudo apt-get install gdal-bin
# install python bindings
sudo apt-get install libgdal-dev
# export some env variables
export CPLUS_INCLUDE_PATH=/usr/include/gdal
export C_INCLUDE_PATH=/usr/include/gdal
# get gdal version:
ogrinfo --version
pip install GDAL== <GDAL VERSION FROM OGRINFO>
The tiled Landsat8 30+ year mosaic was downloaded to the instance using AWS CLI:
aws s3 cp s3://dea-public-data/bare-earth bare-earth --recursive --no-sign-request
Tiles in each band were then identified and merged into a single geotiff:
# import libraries
import os
import rasterio
from rasterio.merge import merge
import numpy as np
import glob
# link directory
fp="bare-earth/combined"
# make a list of landsat bands to merge
bands = ['red','green','blue','nir','swir1','swir2']
# list of files:
fn_lst = glob.glob('bare-earth/combined/**/*.tif', recursive=True)
print(len(fn_lst))
# loop through bands
for band in bands:
print(band)
# get list of files with current band
fns = [x for x in fn_lst if band in x]
src_files_to_mosaic = []
# loop through files and append to a src list for mosaicing
for fn in fns:
src = rasterio.open(fn)
src_files_to_mosaic.append(src)
# build the mosaic
mosaic, out_trans = merge(src_files_to_mosaic)
# make new file name
outfn = os.path.join(fp, 'landsat_30y_barest_earth_%s.tif'%(band))
# edit the metadata
out_meta = src.meta.copy()
out_meta.update({"driver": "GTiff",
"height": mosaic.shape[1],
"width": mosaic.shape[2],
"transform": out_trans,
"crs": src.crs,
})
with rasterio.open(outfn, "w", **out_meta) as dest:
dest.write(mosaic)
src.close()
dest.close()
This was done using python GDAL wrapper functions. Each band operation required 60GB of RAM. This process was single threaded so did not make use of the available compute. The process took 10 hours, resulting in six geotiffs representing each spectral band, each being 49GB.
To unify these six bands, a virtual raster (VRT) was created. This VRT acts as a pointer to pixel data for further geospatial operations without requiring much memory or disk space. Creating the VRT is nearly instantaneous.
gdalbuildvrt -separate landsat8_30y_merge.vrt *.tif
The unified VRT was then converted to a single geotiff using GDAL commands. By utilising the creation-option arguments to the GDAL call, we can ensure that the resultant geotiff is cloud optimised:
gdal_translate landsat8_30y_merge.vrt landsat8_30y_merge.tif -co TILED=YES -co COPY_SRC_OVERVIEWS=YES -co COMPRESS=DEFLATE -co BIGTIFF=YES
This results in a single, 128GB COG. Note that the size is not 6 bands x 49GB/band = 294GB because of compression applied during the GDAL command. The final raster contains 156 billion pixels across the six bands. The COG was transferred to S3 storage.
Access using Jupyter notebook
rasterio is a Python module that reads and writes geospatial raster data. It has native COG support and some handy hooks to open virtual files and files that can be accessed using Get requests including rasters stored on S3.
We developed a Jupyter notebook that uses a Python environment with appropriate packages to:
- Load an Area Of Interest polygon shape file
- Convert it to the coordinate system of the COG Open the link to the COG anddownload the tiles that are coincident with the AOI
- Clip the data to the AOI
- Save the result to a local geotiff
This works as expected and is suitably fast; data for a 25km x 25km polygon takes about 8 seconds to be returned:
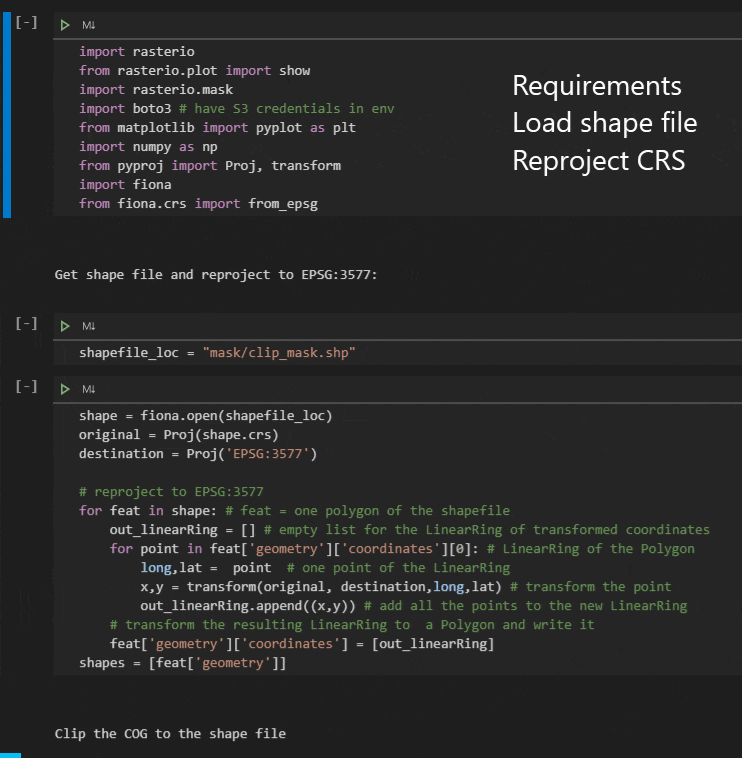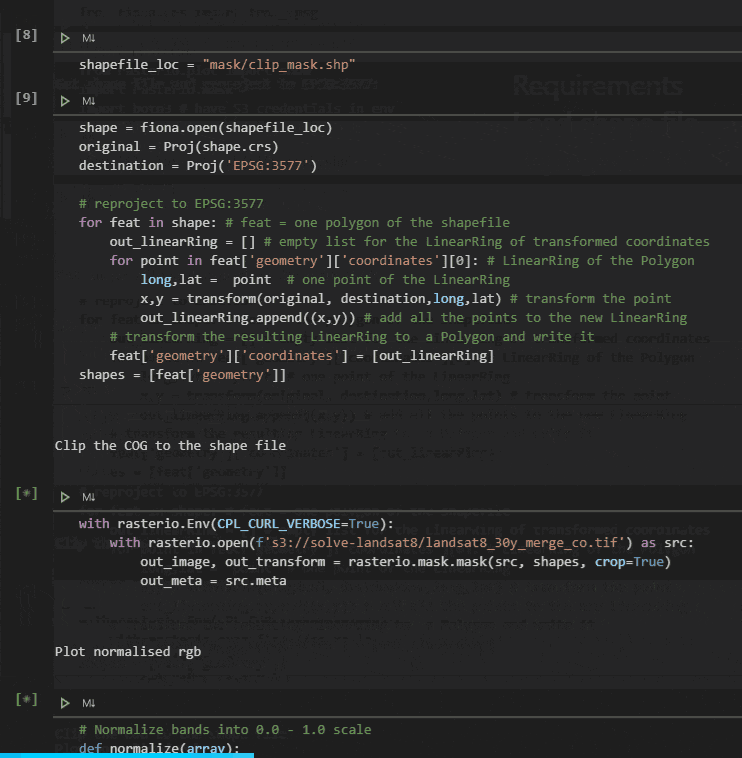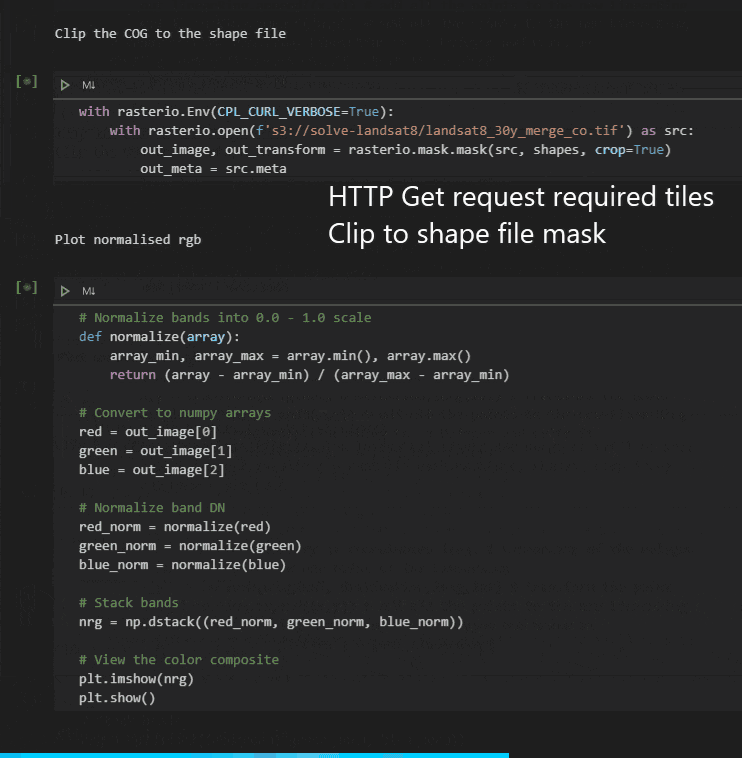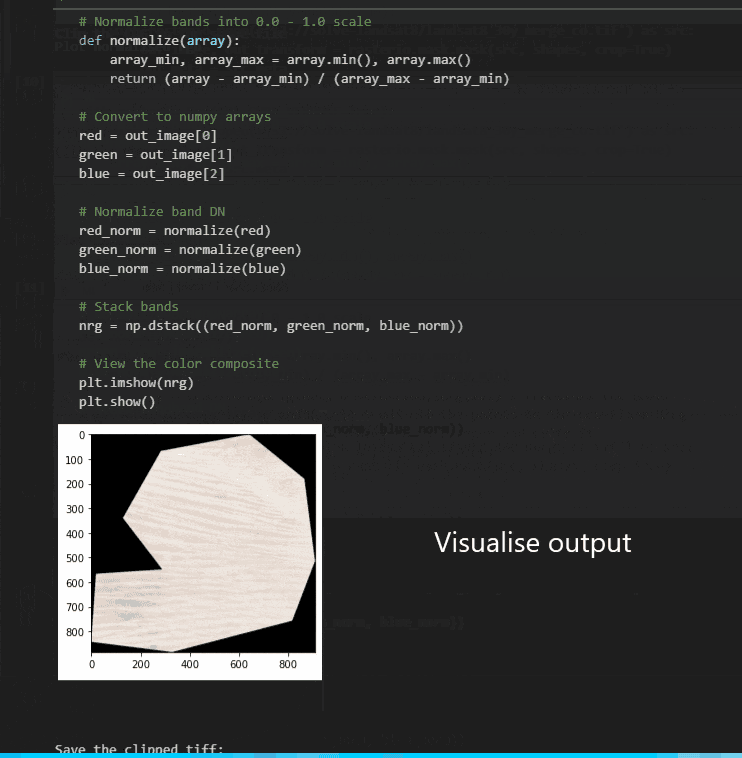
However, we all know that not everyone has the same packages, versions or environments set up, so we decided to push this a step further to make it much more accessible.
AWS Lambda
There are several options to make the process and outcome more accessible, including building and distributing a docker container to our staff, or running the code on a cloud compute instance.
However, we settled on a serverless data processing system using AWS Lambda. Lambda handles server provisioning, management, and scaling, while charging only for the code execution time. Our code will be triggered by an event; in our case whenever a new AIO polygon is uploaded to a particular S3 storage bucket.

The way this works is:
- Configure an environment and packages that the environment depends on to perform our raster operation
- That environment is saved in Lambda conformant “layers” that get attached to a base system configuration
- Lambda is triggered by uploading to S3
- A handler function takes the trigger event details and performs the clip of the Landsat COG
- The clip is then pushed back to S3
- The compute assigned by the Lambda invocation is deallocated
Building dependencies
The default Python environment that starts with Lambda sessions does not come with the required packages that we use to perform the geospatial operations.
Fortunately, this is not the first time people have done this sort of thing. Geolambda gets us a long way to having our geospatial dependencies set up and ready for use in Lambda, but not all the way there!
Geolambda contains all the system libraries required for our script (GDAL, PROJ.5, GEOS) so no modifications to the docker build instructions. However, some of the Python packages that we need are missing. So first, we modify the Python requirements to include fiona (OGR API for Python) and specific a specific version of pyproj:
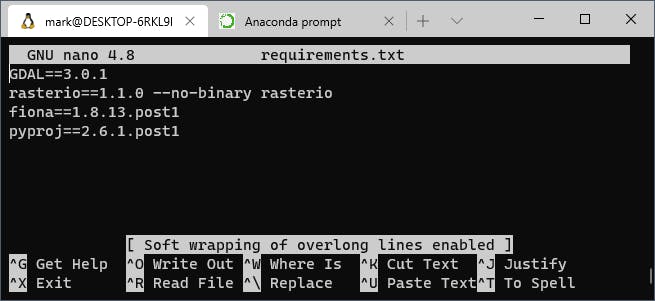
Building the modified docker image then installs all required Python packages and their dependencies into a neat directory structure. We used Ubuntu via WSL2 to build and run the docker containers:
docker build . --build-arg VERSION=2.0.0 --build-arg PYVERSION=3.7.4 -t landsat8_30y_clip:latest
The system libraries and the Python packages are then zipped by running a script inside the docker container:
# system libraries:
docker run --rm -v $PWD:/home/geolambda -it developmentseed/geolambda:2.0.0 package.sh
# python packages:
docker run -v ${PWD}:/home/geolambda -t landsat8_30y_clip:latest package-python.sh
The two resulting zip files with all system libraries and Python packages form the dependency layers in AWS Lambda.
Lambda function
We can now set up a Lambda function using these layers, using an S3 event as a trigger. The Python notebook is easily converted to a handler function that takes event details that are sent to it from the trigger. Pseudo-code for the function is shown:
import dependencies
# set location of proj libraries from /python layer
os.environ['PROJ_LIB'] = '/python/proj'
# reproject the shape file
def lambda_handler(event):
download_from_S3(event)
shape_file = unzip(event)
open(shape_file)
reproject(shape_file)
open(landsat_merge)
raster_out = clip(landsat_merge, shape_file)
save(raster_out)
upload_to_S3(raster_out)
The only differences between the Jupyter notebook and this are the conversion of event details to an S3 location, and unzipping of the file containing the shape file.
Our trigger is configured to listen to *.zip files that are put on a specific S3 bucket. The zip files contain a shape file of the AIO. The trigger sends the S3 location of the uploaded zip file to the lambda function which executes the Landsat mosaic clip and returns the clipped raster to S3.
The finished product:
Summary
This post details one way how we here at Solve take quite large raster products and make them a little more accessible as required for our projects.
The tools, libraries and packages we utilised were: AWS S3 and Lambda, GDAL, Python + Jupyter notebooks, rasterio and fiona, WSL2 + Ubuntu, Docker and geolambda.
The data used was from the joint Australian National University and Geoscience Australia effort to create a barest-earth model of Landsat data products spanning multiple decades. We feel the significance of this and similar datasets and will be realised in the coming years, and we appreciate Geoscience Australia for hosting the data.
References
Siegal, B. S. & Goetz, A. F. Effect of vegetation on rock and soil type discrimination. Photogramm. Eng. Remote Sens. 43, 191–196 (1977)
Roberts, D., Wilford, J. & Ghattas, O. Exposed soil and mineral map of the Australian continent revealing the land at its barest. Nat Commun 10, 5297 (2019). doi.org/10.1038/s41467-019-13276-1