
Substring search in Elasticsearch


Consider a scenario when you need to replicate a SQL query having a LIKE operator, or you want to perform a partial match or a substring match using elasticsearch.
In these cases, you might wonder how to achieve them. As the commonly used queries like the match, term, multi-match queries with a standard analyzer will not help you achieve this task. You will need to use either wildcard query, query_string or you have to configure your index with some custom analyzer and tokenizers.
Some ways to do a substring search
Suppose the following data is indexed in your index. Your task is to find all those documents that contain foo


 This task can be done in different ways, according to your use cases. But three of the methods are shown below.
This task can be done in different ways, according to your use cases. But three of the methods are shown below.
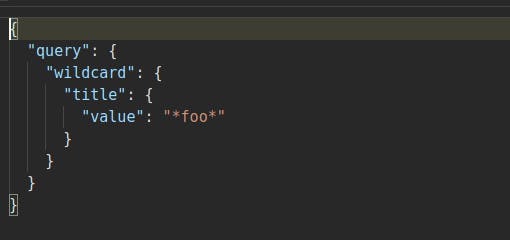
Wildcard query
It is a term-level query. This query returns those documents that match the specified wildcard pattern. The wildcard expression is not analyzed. It only evaluates either
*or?.
- For example:
*foo?arwould match "myfoobar", "asfoozar", etc.*can be any number of characters whereas?represents only a single character
- Leading wildcard queries should be avoided as it leads to the scanning of the entire index. This is because leading wildcards increases the number of iterations required to get the matched documents.
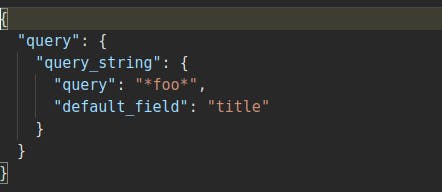
Query string
This query returns documents based on a given query string. In query_string also, you can use wildcard search along with * or ?.Wildcards along with query_string should be used very wisely, as it can affect the cluster performance badly.
Note: Query string and wildcard query both can be slow on bigger data sets. You should look into using ngram or edge ngrams to improve the speed issues.
N-gram tokenizer
Ngrams and edge ngrams are two very unique ways of tokenizing text in elasticsearch. This tokenizer tokenizes the words into multiple subtokens of a specified length. This length depends on the value of min_gram and max_gram. These settings control the size of the token that is generated. Based on these indexed tokens the respective document matches.
Index Mapping for generating ngrams would be -
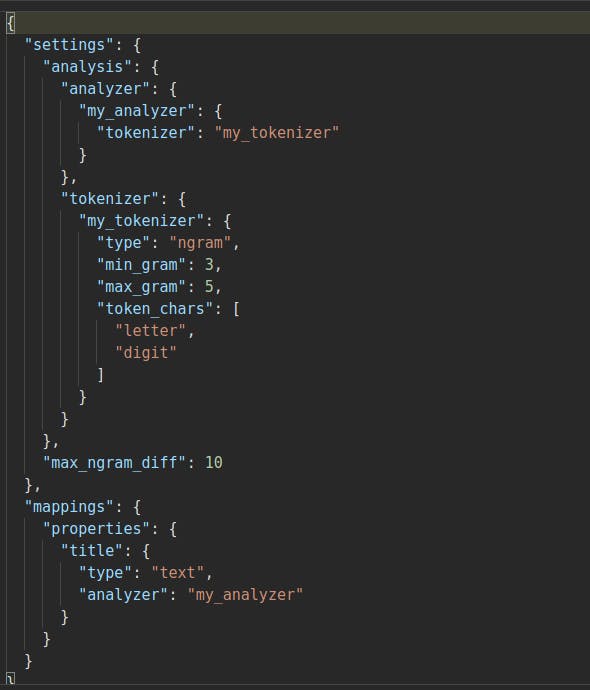
You can check the tokens generated by using Analyze API. For example: myfoobar will generate tokens like "foo", "foob", "fooba", "oba", etc.
Search Query -
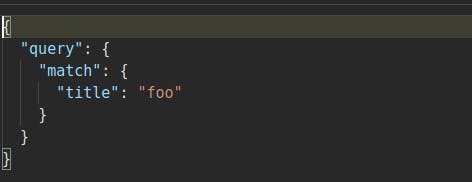
All the three queries shown above will give all the three documents in the search result.