Abu Precious O.btere.hashnode.dev·Dec 3, 2024Understanding ML Inference Latency and ML Services LatencyIn the world of machine learning (ML), achieving quick results is critical, especially in real-time applications like autonomous driving, recommendation systems, and interactive voice assistants. But often, discussions about ML performance focus on a...low-latency
Siddartha Pullakhandamsiddartha10.hashnode.dev·Sep 5, 2024Getting Started with QuantizationWhat is Quantization? It is the process of reducing/mapping higher precision weights and activations into lower precision. In simple terms shrinking a model to smaller size that can be used to run on resources with limited memory. Linear Quantizatio...11 likes·51 readsquantization
Kevin Loggenbergblog.thecodesmith.co.za·Jul 9, 2024Local LLM's with .NetIntroduction In this article we will explore performing inference on GGUF models with Llama.cpp using the Llamasharp nuget package. It sounds like it should take longer than it actually does. GGUF models are probably one of the easiest models to work...240 readsLlamaSharp
Spheron NetworkforSpheron's Blogblog.spheron.network·Jun 5, 2024Understanding Deep Learning: Training, Inference, and GPU Shortage ChallengesDeep learning has revolutionized numerous fields, including computer vision, natural language processing, and speech recognition. However, the power of deep learning comes at a cost – the computational demands are immense, both during the training an...87 readsDeep LearningDeep Learning
Venkat Ramanvenkat.eu·May 31, 2024Essential Math & Concepts for LLM Inference(Image Credit: HF TGI Benchmark) Introduction As enterprises and tech enthusiasts increasingly integrate LLM applications into their daily workflows, the demand for TFLOPS is ever increasing. Apple, Microsoft, Google, and Samsung have already introdu...415 readsAI
Haocheng Linhaochengcodedev.hashnode.dev·Apr 30, 2024Understanding and Calculating the Variance of Sample MeanIntroduction When working with a set of data points, understanding the variability within the data is crucial for drawing meaningful conclusions. One fundamental measure of variability is the variance, which quantifies how much the values in a datase...statistics
RJ Honickylearning-exhaust.hashnode.dev·Apr 12, 2024Are All Large Language Models Really in 1.58 Bits?Introduction This post is my learning exhaust from reading an exciting pre-print paper titled The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits about very efficient representations of high-performing LLMs. I am trying to come up to s...3 likes·2.2K readsllm
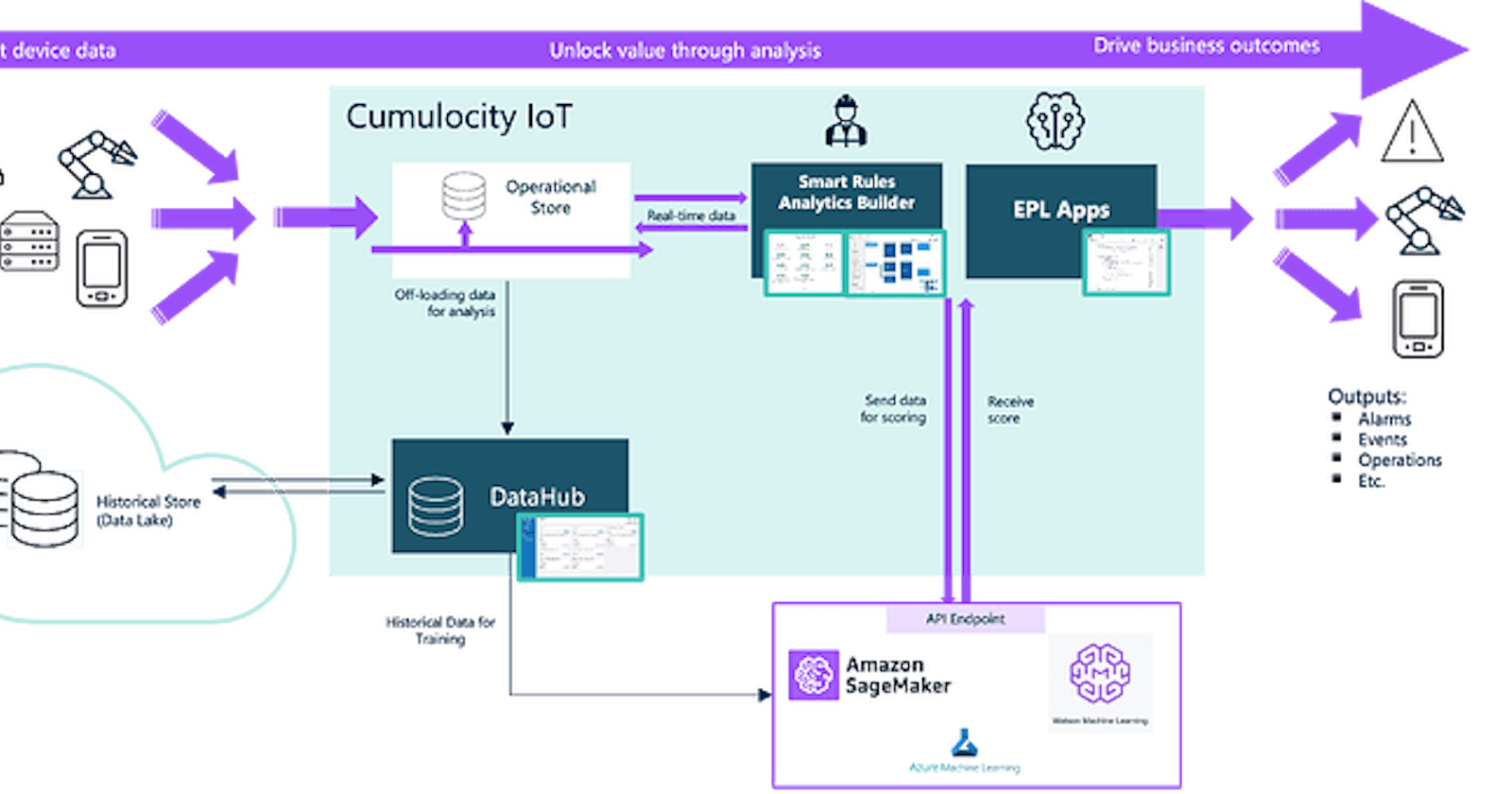
TECHcommunity_SAGtechcommsag.hashnode.dev·Mar 15, 2024Leveraging Hyperscaler Clouds for Machine Learning Inferencing on Cumulocity IoT DataAuthors: @kanishk.chaturvedi@Nick_Van_Damme1 Introduction In the fast-paced world of IoT, processing and analyzing data in real-time is crucial. With billions of devices generating vast amounts of data, leveraging Machine Learning (ML) is key to turn...cumulocity
Kaushal Powarwrittenbykaushal.hashnode.dev·Jan 4, 2024How to convert HF (safetensors) 🤗 model to ggufYou want to convert Huggingface model to gguf format?I was struggling to tackle the same problem a few days ago. I finetuned a Llama 7B model and the model was saved in safetensor format. I wanted to use gguf model so I searched a lot and found a sol...1 like·4.5K readsLLMllamacpp
Nosananosana.hashnode.dev·Oct 18, 2023Nosana's New Direction: AI InferenceToday, we’re excited to share a significant update about the future of Nosana. After careful consideration, we’ve decided to pivot away from CI/CD services. Instead, Nosana will now focus on providing a massive GPU-compute grid for AI inference. The ...GPU