Thread
Popular posts
You're actually thinking about the problem backwards, but that's a common misunderstanding in multithreaded programming.
Back when I was working on some BeWare in the music industry some two decades ago, I had the idea of workers, multithreading, multitasking, and so forth very well explained to me by a co-worker in a way I've rarely ever seen stated so clearly. BeOS was a very strange OS in that it was "pervasively multithreaded" -- EVERY program typically had at LEAST three threads, one for input, one for output, one for logic. The OS was built around the concept that very few things needed or or ever even should work lock-in-step.
The issue at hand is that a LOT of tasks DO NOT work well being broken into smaller threads. They are by their nature linear in how they operate and should remain isolated to a single execution. The king of this is device I/O, of which filesystem access is a part.
Hence the idea is to ONLY parallelize what gains benefits from being in parallel. In this case you have reading data which should only be one thread, that would then hand off to other threads to process said data while it goes off to get MORE. Those other threads for data processing what you've read? Those would be your workers.
Hence your example of reading a 2gb file is perfect for us to work with here. The OPTIMAL way to read a file is a single linear thread of reading it. If you try to break it into pieces you go from fast sequential reads, to slow random reads -- and whilst sure modern SSD's don't have seek times, if you test with something like crystaldiskmark you'll still see that even some of the fastest SSD's in existence still take a huge hit on random reads.
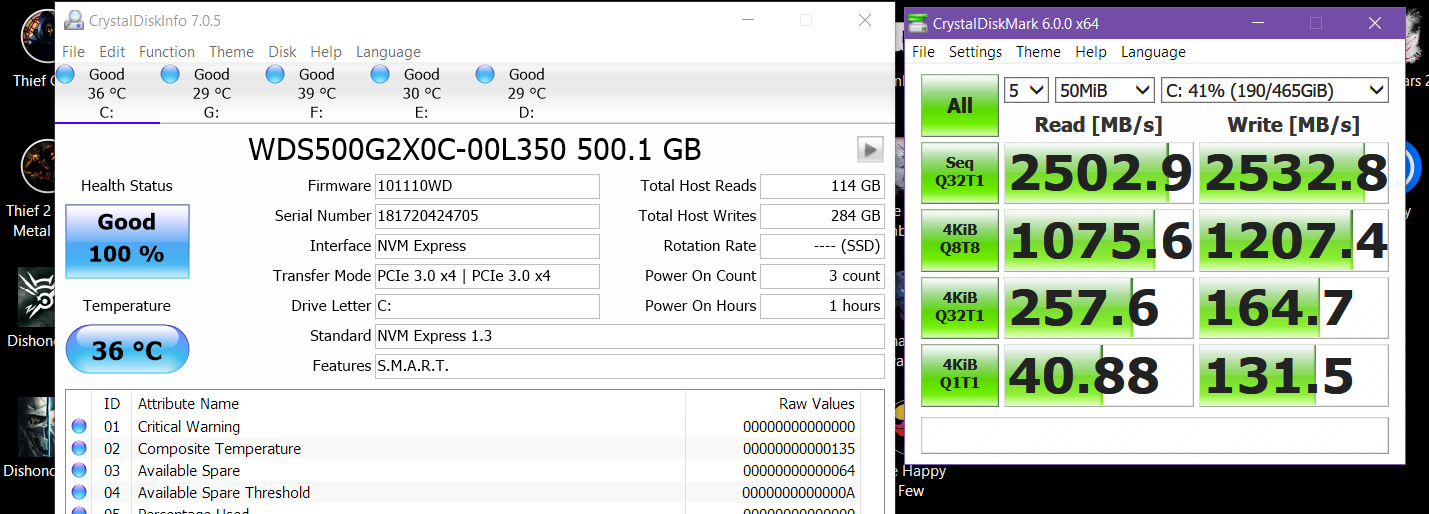
As you can see, the top row -- sequentila read/writes -- is fastest. You want to leverage that when possible so breaking the file into different chunks your going to read out-of-order by different threads would be a performance DOWNGRADE.
What you want to do is run your PROCESSING in parallel with the read, and that's where the concept of workers shine. Your workers would be one or more threads that your file-read loop would send data to, your read loop being a SINGLE thread, possibly part of the executable's main thread.
In the case of your 2gb file let's say it's something like CSV, one record per line, or some other easily handled type of delimited or block based data.
Loop:
Read block from file
Are any workers available?
> No
Are we at maximum allowable workers?
> No, make a worker
> Yes, wait until a worker is available
> Yes
Drop-through, no action needed
Send data to available worker
End Loop
After file end, wait until all workers are complete, then delete the workers.
This approach creates workers as and only when needed, so you aren't creating extra threads you don't need should the read be bottleneck -- which with files it often is.
That's typically the optimal way to handle it. File reads are suspended if the workers are all busy and we don't have the cores to waste time making more, but for the most part file reads run in parallel with your processing.
All a 'worker' being is another thread.
Does that help any? See how thinking about breaking up the file READS into multiple threads doesn't make sense and how you should have one read and one or more data processing threads in parallel with it?