



Overview:
Stream processing is about processing data as it arrives. Unlike “batch processing” businesses don’t have to wait a certain amount of time (usually in hours to a day based on the volume of the data) to store, analyze and get results on the incoming data. This is particularly useful in cases like fraud detection, system monitoring, stock market analysis, website activity tracking and many more. Early detection is key for all these cases hence stream processing is a perfect fit here.
Apache Kafka, a distributed streaming platform, has served as a reliable source of data for stream processing solutions like Apache Spark Streaming, Apache Storm, Apache Samza, Apache Flink. Starting with version 0.10.0, Kafka client libraries also include a powerful stream processing library. Which means there is no need for an external processing framework just to process incoming data which is already available in Kafka.
Here we will see how to implement fraud detection using Apache Kafka streams API. ATM transactions, as they happen, can be streamed to a Kafka Topic. These can then be processed to detect any suspicious activity.
Prerequisites:
Before continuing, you should be aware of the following concepts, core to stream processing:
- Stream – Table Duality
- Time windows in stream processing
- Stream Repartitioning
- Stream-Stream, Stream-Table Join
- Topology
If you are not aware of these concepts, you can read a free book by confluent.io Kafka The Definitive Guide.
Approach:
We will consider a transaction to be suspicious, if
- Two or more transactions have happened on the same account within 10 mins.
- They are done on different ATMs
- The ATMs are located too far apart and cannot be reached in 10 mins or less.
A typical ATM transaction data would contain the following data:
- Account no
- Atm Id
- Time of transaction
- Amount
- Transaction Id.
The first two criteria above should be fairly easy to check with this data. For the last criteria, we will calculate the required speed to reach next atm. If the speed seems to be too great, we will consider it as a suspicious activity.
To calculate the speed between ATMs, we also need geo locations (co-ordinates) of the ATMs. We can use them & find the distance between the two ATMs “as the crow flies”. The distance & timestamps on the transactions can give us the required speed.
Sample Data:
Here is a sample of the data we expect to receive on our topic. It should include the geo location of the ATM in addition to the data mentioned above.
{
"account_id": "a54",
"timestamp": "2018-12-13 11:23:07 +0000",
"atm": "ATM : 301736434",
"amount": 50,
"location": {"lat": "53.7916054", "lon": "-1.7471223"},
"transaction_id": "77620dac-fec9-11e8-9027-0242ac1c0007"
}
Implementation:
Create Project:
First, we need to create a project for our application. I am using Maven
as my build tool. So, I created a pom.xml file inside my project
directory & added kafka-streams as a dependency.
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>
You can find the entire project on github.
Main Class:
ATMFraud.java contains the main method for the application. It starts off by creating a list of property entries needed for connecting to message broker.
Properties properties = new Properties();
properties.put(APPLICATION_ID_CONFIG, "streams-atm-fraud-detector");
properties.put(BOOTSTRAP_SERVERS_CONFIG, "kafka:9092");
properties.put(DEFAULT_KEY_SERDE_CLASS_CONFIG, String().getClass());
properties.put(DEFAULT_VALUE_SERDE_CLASS_CONFIG, AtmTransactionSerde().getClass());
Note that, I am running Kafka separately on my machine. The application code here does not start/stop Kafka with it. That is something I plan to add later. As of now, it is not included.
StreamsBuilder class lets us connect to a Kafka Topic & read its
contents as a Stream. Below we connect to the topic
my_atm_txns_gess as a stream & filter any null messages. We then
re-partition the stream to have a useful key i.e. Account id.
final StreamsBuilder streamsBuilder = new StreamsBuilder();
final KStream<String, AtmTransaction> stream1 = streamsBuilder
.stream("my_atm_txns_gess", Consumed.with(String(),
AtmTransactionSerde(),
new ATMTransactionTimestampExtractor(),
Topology.AutoOffsetReset.EARLIEST))
.filter(((key, value) -> value != null))
.map((key, value) -> KeyValue.pair(value.getAccountId(), value));
The stream method above accepts
- Name of the topic to connect to.
- Key & Value Serdes (A short name by Kafka for serializer & deserializer pair)
- A
TimestampExtractorimplementor class object; required for correct windowing of the messages. - And an
AutoOffsetResetwhich lets you choose where to start reading messages from i.e., from the beginning or end.
AtmTransaction is the class representing data in the
Topic. AtmTransactionSerde is serde for this class. To find two
transactions on the same account, we join the stream with a copy of
itself. We use map method to create a copy of the stream.
final KStream<String, AtmTransaction> stream2 = stream1.map((KeyValue::pair));
Now we can join these two streams to get a JoinedAtmTransactions. The
join should consider:
- all transactions after 10 mins of the current transaction in the first stream
- no transaction before the timestamp on current transaction.
This will ensure that we join the later transaction with earlier one. We ignore the join other way round.
final KStream<String, JoinedAtmTransactions> joinedStream = stream1.join(stream2,
JoinedAtmTransactions::new,
JoinWindows.of(Duration.ofMinutes(10)).before(Duration.ZERO));
Joined Atm Transactions:
I structured the JoinedAtmTransactions as below. The
method calculateDistanceInKM calculates the distance between the
given co-ordinates.
public class JoinedAtmTransactions {
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss Z")
@JsonProperty("prev_timestamp")
private Date prevTimestamp;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss Z")
@JsonProperty("later_timestamp")
private Date laterTimestamp;
@JsonProperty("distance_between_trxns_KM")
private double distanceBetweenTrxnsKM;
@JsonProperty("millisecond_difference")
private long millisecondDifference;
@JsonProperty("minutes_difference")
private double minutesDifference;
@JsonProperty("KMH_required")
private double KMHRequired;
@JsonProperty("account_id")
private String accountId;
@JsonProperty("prev_transaction_id")
private UUID prevTransactionId;
@JsonProperty("later_transaction_id")
private UUID laterTransactionId;
@JsonProperty("prev_transaction_location")
private Location prevTransactionLocation;
@JsonProperty("later_transaction_location")
private Location laterTransactionLocation;
public JoinedAtmTransactions(final AtmTransaction prevTrxn, final AtmTransaction laterTrxn) {
prevTimestamp = prevTrxn.getTimestamp();
laterTimestamp = laterTrxn.getTimestamp();
distanceBetweenTrxnsKM = calculateDistanceInKM(prevTrxn.getLocation().getLat(),
prevTrxn.getLocation().getLon(),
laterTrxn.getLocation().getLat(),
laterTrxn.getLocation().getLon());
millisecondDifference = laterTrxn.getTimestamp().getTime() - prevTrxn.getTimestamp().getTime();
minutesDifference = (double) millisecondDifference / (1000 * 60);
KMHRequired = distanceBetweenTrxnsKM / (minutesDifference/60);
accountId = prevTrxn.getAccountId();
prevTransactionId = prevTrxn.getTransactionId();
laterTransactionId = laterTrxn.getTransactionId();
prevTransactionLocation = prevTrxn.getLocation();
laterTransactionLocation = laterTrxn.getLocation();
}
private double calculateDistanceInKM(double lat1, double lon1, double lat2, double lon2) {
double d2r = (PI/180);
double distance = 0;
try {
final double dlat = (lat2 - lat1) * d2r;
final double dlong = (lon2 - lon1) * d2r;
final double a = pow(sin(dlat / 2), 2) + cos(lat1 * d2r) * cos(lat2 * d2r) * pow(sin(dlong / 2.0), 2);
final double c = 2 * atan2(sqrt(a), sqrt(1 - a));
distance = 6367 * c;
} catch (Exception e) {
e.printStackTrace();
}
return distance;
}
...
}
Filter the join results:
We are now ready to filter the joinedStream to find suspicious
transactions. We will use the criteria mentioned in the approach
section.
public class ATMFraud {
...
final KStream<String, JoinedAtmTransactions> filteredStream = joinedStream.filter(((accountId, joinedTrxn) ->
{
boolean result = false;
if (joinedTrxn.getPrevTransactionId().equals(joinedTrxn.getLaterTransactionId()))
System.out.println("transaction IDS match. record will be skipped. Prev Trxn Id: " + joinedTrxn.getPrevTransactionId()
+ "Later Trxn Id: " + joinedTrxn.getLaterTransactionId());
else if (joinedTrxn.getPrevTimestamp().equals(joinedTrxn.getLaterTimestamp()))
System.out.println("transaction TIMES match. record will be skipped. Prev Trxn Id: " + joinedTrxn.getPrevTransactionId()
+ "Later Trxn Id: " + joinedTrxn.getLaterTransactionId());
else if (joinedTrxn.getPrevTransactionLocation().toString().equals(joinedTrxn.getLaterTransactionLocation().toString()))
System.out.println("transaction LOCATIONS match. record will be skipped. Prev Trxn Id: " + joinedTrxn.getPrevTransactionId()
+ "Later Trxn Id: " + joinedTrxn.getLaterTransactionId());
else {
System.out.println("FRAUDULOUS transaction found. Prev Trxn Id: " + joinedTrxn.getPrevTransactionId()
+ "Later Trxn Id: " + joinedTrxn.getLaterTransactionId());
result = true;
}
return result;
}));
...
}
Entries in the filtered stream are suspicious transactions. We will post
them to my_atm_txns_fraudulent stream. Some other app can listen to
this topic & take needed actions. For demo purpose, I will print these
transactions before posting to the my_atm_txns_fraudulent stream. I
can do that using mapValues operation, as below.
final KStream<String, JoinedAtmTransactions> printFraudTrxnsStream = filteredStream.mapValues(value -> {
System.out.println("--------------------------------------------------------------------------------------------");
System.out.println("Fraudulent transaction: " + value);
return value;
});
printFraudTrxnsStream.to("my_atm_txns_fraudulent", Produced.with(String(), JoinedAtmTransactionsSerde()));
Connect and start listening to messages:
This last piece of code is very important. This will enable us to start
listening to the input topic. We first build the topology of the streams
& print the same to the console. Then we use the topology & properties
to create an instance of KafkaStreams. The shutdown hook lets us close
the streams before exiting the application. Lastly, we start
the kafkaStreams & wait till the program is asked to stop.
final Topology topology = streamsBuilder.build();
System.out.println(topology.describe());
final KafkaStreams kafkaStreams = new KafkaStreams(topology, properties);
final CountDownLatch latch = new CountDownLatch(1);
getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
kafkaStreams.close();
latch.countDown();
}
});
try {
kafkaStreams.start();
latch.await();
} catch (Throwable t) {
System.exit(1);
}
System.exit(0);
Result:
The application can be run using mvn clean package exec:java
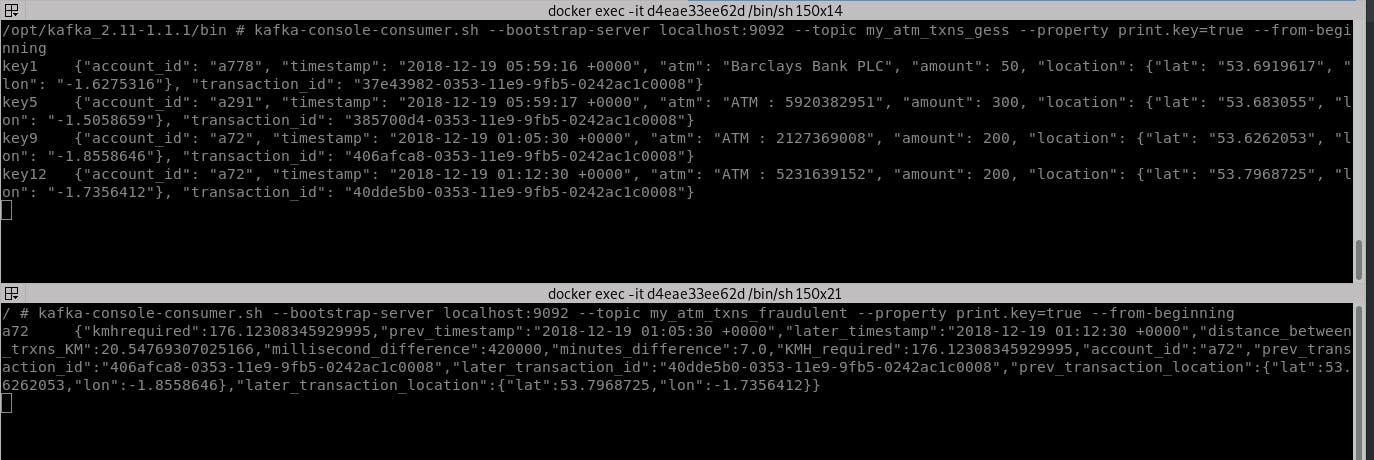
-Dexec.mainClass=myapps.ATMFraud command. Image below shows the output
that you should get when Kafka is posted with ATM transaction as shown.
The console on the top is running Kafka console consumer, listening to
the source topic i.e. my_atm_txns_gess. The console on the bottom is
doing the same, listening to the result topic i.e.
my_atm_txns_fraudulent.
There are 4 transactions posted to the source topic out of which the last two are on the same account & fit the suspicious activity criteria. As you can see in the bottom console, our application correctly identified the suspicious activity & posted on the result topic.
References:
- This blog post uses Ksql to implement a similar use case for fraud detection and this article is inspired from this post
- A good start if you want to get familiar with basic concepts around Kafka platform
- An introduction video on Kafka streams.
- Documentation of the Kafka streams
On an unrelated note, if you want to learn more about auditing Kubernetes clusters check out this blog post.