

Building a react x electron code editor pt.3 - creating a basic lexer and visualising tokens


recap
Last post we were looking at tokenization and how the code editor would approach syntax highlighting. We established the lexer library would be language-agnostic and rely on the language grammar to be plugged in. The tokeniser function would look something like this:
function tokenise(text: string, plugin: Plugin): Token[] {
...
// tokenising ongoing...
...
return tokens
}
NOTE: moving to Typescript
I completely migrated the project to typescript and I can't recommend it enough. Code is now clear, typed and modular packages can actually be easily understood with typed interfaces.
writing a basic javascript grammar
To write a grammar we have to learn a bit of RegEx. Language rules consist of a token name and a RegEx rule to match the text. For example, the simplest we could do would be to match every number with a rule like this:
{
"name": "number",
"rule": "/d"
}
More complicated rules could be a function call identifier:
{
"name": "function-identifier",
"rule": "\\b[a-z_]([a-zA-Z0-9_]+)?(?=\\()",
}
In this case the Regex looks for:
\ba word boundary start.[a-z_]one lowercase letter or underscore.([a-zA-Z0-9_]+)?Followed by an optional number of lower, uppercase, numbers or underscores.(?=\()Preceded by a parentheses.
note: In json backslashes are escaped by another backslash.
We can add more and more rules like this to our grammars to compile a comprehensive javascript tokeniser.
creating the Lexer class
So let's start with a Lexer.ts defining some interfaces:
/**
* Typescript namespace for the Lexer interfaces.
*/
export declare namespace Lexer {
/**
* A Plugin in the lexer is a Language grammar with an id and a list of Grammar rules
*/
export interface Plugin {
id: string,
grammars: { [key: string]: Grammar }
}
/**
* A Grammar defines a RegEx rule and its name identifier.
*/
export interface Grammar {
name: string | null,
rule: string | null,
}
/**
* An identified set of characters matched by a grammar in the Lexer
*/
export interface Token {
name: string,
value: string,
index: number
}
}
We have a Plugin object which is the language lexical grammar, made of an id and a keyed object of Grammars, the rules that define a Token.
The token object has a name, value and a start index.
Now let's create the Lexer class:
/**typescript
* The Lexer class performs lexical analysis, tokenisation and contains helper methods for parsing text.
*/
export class Lexer {
}
Our tokenise function will:
- iterate through the plugin's grammar and apply the rule to the given text.
- If there are match results, create a token and push it to an array we initialise.
- Finally sort the array by index to have them in their natural order.
/**
* Tokenises the given text into a {@link Token} array.using a given {@link Plugin}.
* @param text Text to tokenise.
* @param plugin Plugin language to apply grammars from.
*
* @returns Token array.
*/
tokenise(text: string, plugin: Lexer.Plugin): Lexer.Token[] {
// create an array from the grammars object,
// ATT use <any> hack for ES6 ts to discover the values method,
// @see stackoverflow.com/questions/42166914/there…
const grammars = (<any>Object).values(plugin.grammars)
// create a new array to store the tokens,
const tokens: Lexer.Token[] = []
// for each lang grammar,
grammars.forEach((grammar: Lexer.Grammar) => {
// init a lexical grammar rule,
var rule = grammar.rule
// create the regex from the feature match regex,
const regex = new RegExp(rule, 'gms')
// nullable array to store match results,
var matchResults: RegExpExecArray
// loop until null the match expression to get every regex match result,
while ((matchResults = regex.exec(text)) !== null) {
tokens.push({
name: grammar.name,
value: matchResults[0],
index: regex.lastIndex - matchResults[0].length
})
}
})
// sort tokens by their natural index order,
tokens.sort((a, b) => a.index - b.index)
return tokens
}
}
visualising our tokens
It's hard to see what you are doing in code sometimes without some good html to visualise what's happening. We have to create a React component, let's call it Editor, which generates lines of text vertically, themselves mapping tokens horizontally. That will sort of resemble a text editor!
export default function Editor(props: EditorProps) {
return (
<div className="editor">
{
props.lines.map(line => <Line value={line} plugin={props.plugin}/>
}
</div>
)
}
export default function Line(props: LineProps) {
const lexer = useMemo(() => new Lexer(), [])
// Memoize the tokenisation operation on this Line.
const tokens = useMemo(() => {
// skip if plugin is null,
if (props.plugin !== null) {
return lexer.tokenise(props.value, props.plugin)
} else {
return []
}
},
// dep on the value or plugin,
[props.value, props.plugin])
return (
<div className="line">
{
tokens.map((token, index) => <span key={index} className={'token ' + token.name}>{token.value}</span>)
}
</div>
)
}
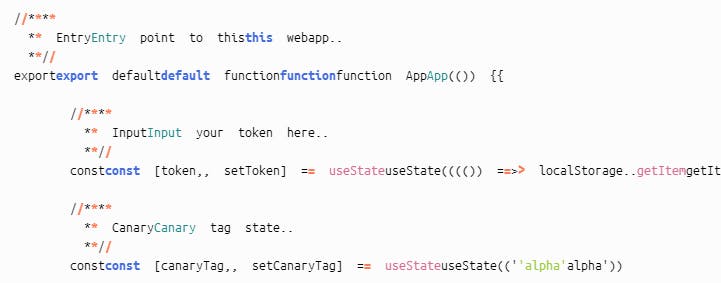
Ouch what happened here?
There is one more step before having a properly tokenised text. Right now our lexer will generate duplicate tokens that fall into two or more categories, such as an identifier and keywords!
We want to add a reducer function that combines duplicate tokens into one with the different names in a hierarchy of importance. For example an 'identifier' token is superseded by a 'keyword' function, as we should always highlight a lexeme as a keyword instead of a default identifier.
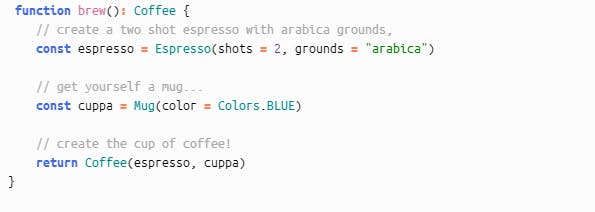
Now this can be done in many ways, I'll leave here what I have done for now:
// init a previous token to hold the last indexed token,
var previousToken: Lexer.Token = {
index: 0,
name: "",
value: "",
}
// reduce repeated tokens by index,
const reducer = tokens.reduce(
(acc: Lexer.Token[],
token: Lexer.Token) => {
// end index,
const prevEndIndex = previousToken.index + previousToken.value.length
const endIndex = token.index + token.value.length
// if the start index is the same...
if (token.index === previousToken.index) {
// the new token might consume the old one, so pop the previous token,
if (endIndex >= prevEndIndex) {
acc.pop()
}
// if this new token's end is the same as the previous one...
if (endIndex === prevEndIndex) {
// chain the token names since they start at the same index,
token.name = token.name + ' ' + previousToken.name
// push this new token instead,
acc.push(token)
// assign the previous token to this one,
previousToken = token
}
}
// if this new token's index consumes the previous one...
if (endIndex > prevEndIndex) {
// push this new token instead,
acc.push(token)
// assign the previous token to this one,
previousToken = token
}
// return the accumulator,
return acc
},
[])
Next steps
With a basic lexer going, next time we will look at implementing the editor properly in React.