



In this tutorial, you will learn some techniques that you can use to clean data in Python using Pandas. Now, data is often, more or less, chaotic. When we get, or collect, or data we might not think of structuring it in the right way. Or the data source was messy. Therefore, when we are getting our hands on a new dataset, it's often inevitable that you will need to clean data.
Pandas is a Python package that provide powerful methods to, among many things, diagnose and clean messy datasets. While there's far more we can do with Pandas and Python, in this tutorial we will focus on learning how to:
- Import comma-separated values (CSV) to a dataframe
- Clean values (e.g., change data type)
- Clean up column names
- Drop unneccessary variables (i.e., delete columns)
And more!
What is Messy Data?
You might wonder what is clean data? Well, clean data is accurate, complete, and is ready for us to analyze. Here are some examples of what distinguish clean data:
- No duplicate rows/values
- Error-free (e.g. free of misspellings)
- Relevant (e.g. free of special characters, unnecessary variables)
- The appropriate data type for analysis
- Free of outliers (or outliers known)
- No missing data (depending on what analysis you will do, later)
Requirements
To clean data in Python using Pandas we need to install Pandas. Here is how you can install Pandas using pip: pip install pandas.
Import Data from CSV using read_csv
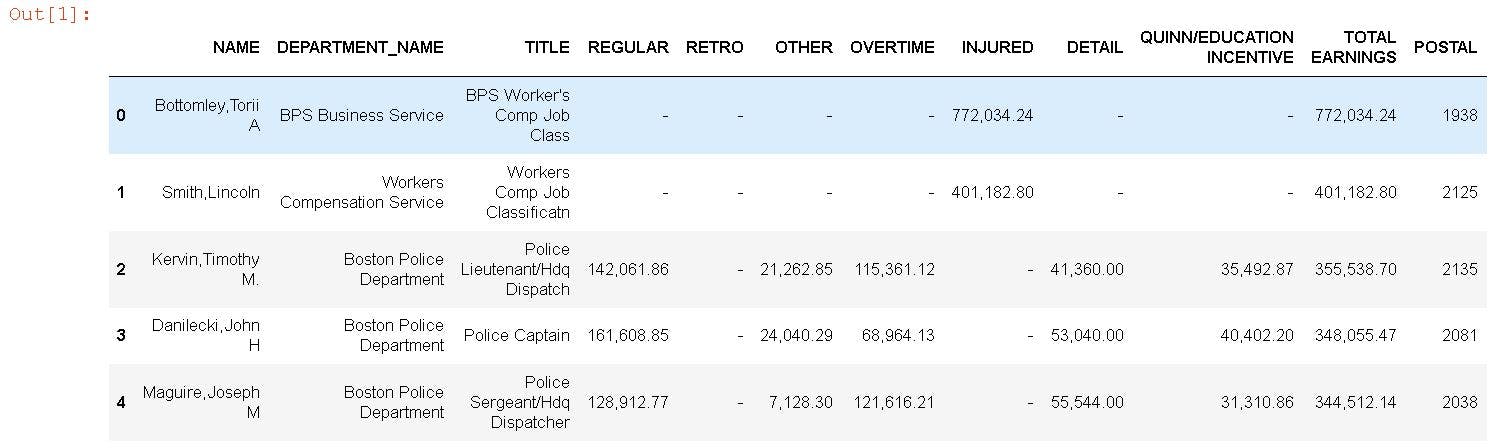
Let's have a look at the example data set. We will in read the .csv file with Pandas read_csv() and then have a quick look at the dataframe.
import pandas as pd
df = pd.read_csv('allemployeescy2019_feb19_20final-all.csv')
df.head()
We can also obtain some information about the structure of the dataframe by using the .info() method. This method is much like the glimpse() function of dplyr in R and will show us the column/variable names, the data types of each variable. Furthermore, we can also see that there are 12 columns and 23312 rows (entries).
df.info()
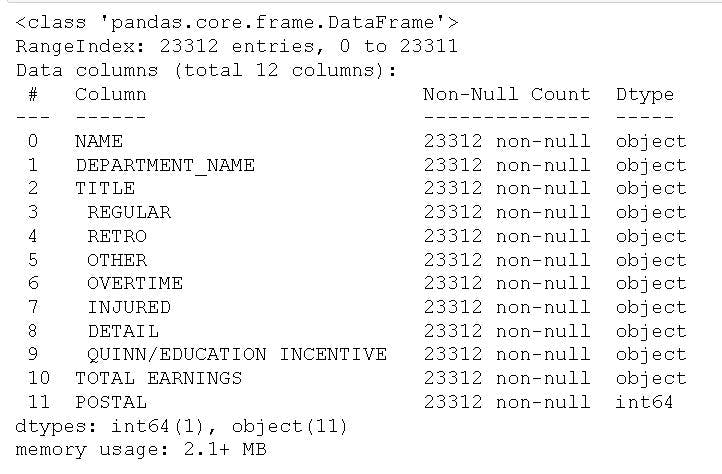
Finally, we can see that there's only one column that is of integer data type and that there are values that are numeric but is of object type in the dataframe. We need to fix this, among other things, before we can carry out our data analysis. First, we need to change the "-" to missing values. Second, we need to remove the "," from the number (thousands).
Cleaning Values and Changing Data Type in Columns in Pandas Dataframe
First, we need to remove the whitespaces surrounding the "-" sign and replace it with nan. To our help, here, we will import NumPy and use the np.NaN method as well as the .replace() method. Furthermore, we will remove the comma and change the data type to float. Here we will make use of a couple of methods. First, we will select the column using iloc. Second, we will use the apply method on these columns and use a lambda to replace the commas. Finally, we will use the .astype() method and change the data type to float.
import numpy as np
df.replace(r'\s*-', np.nan, regex=True,
inplace=True)
df.iloc[:,3:11].apply(lambda x: x.str.replace(',', '').astype(float), axis=1)
Running the above code makes it clear that we have more cleaning to do! Actually, we need to remove parentheses as well. We can, again, do this using regular expressions and the replace method (as in line 2, above, if you have not noticed).
df.replace(r'[()]', np.nan, regex=True,
inplace=True)
df.iloc[:,3:11] = df.iloc[:,3:11].apply(lambda x: x.str.replace(',', '').astype(float), axis=1)
That should have done the trick! We can, again, have a look at the structure of the dataframe. See below how we now have float data types in the columns.
df.info()
Cleaning Column names (i.e., renaming variables)
It may not be clear but the column names are also containing white spaces. Have a look at the output above. Notice how the columns from REGULAR to QUINN/EDUCATION INCENTIVE is somewhat indented. At least, more than the other columns. This indicates that there are whitespaces in the column names. Here's how we can replace the white spaces in the column names:
# Rename columns i.e. replace whitespaces
df.columns = df.columns.str.replace(' ', '')
df.info()
Nice! It seems like we manage to remove it, judging of the output above.
Uppercase to Lowercase in the Column Names
Let's do some more data cleaning. We will now change the column names to lower case using list comprehension.
df.columns = [column.lower() for column in df.columns]
# get the column names as a list
list(df.columns)

Again, by printing a list of column names (in the Pandas dataframe) we can see that we have removed the column "postal". I have learned how to get the column names from Pandas dataframe from this blog post: https://www.marsja.se/how-to-get-the-column-names-from-a-pandas-dataframe-print-and-list/. Check it out!
Removing Missing Values
There's probably a lot of missing values now in our dataset. Let's have a look!
df.isna().sum()
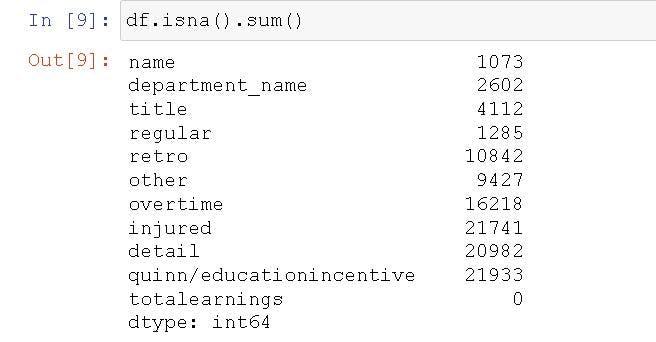
This is probably way to many, in each variable, to remove. This means that some of the variables might not be useful to analyze at all! It might also be too many to impute.
Right! That was it. Hope you learned something great!