Concurrent Programming in Python is not what you think it is.


In this article, I will first walk you through the distinction between concurrent programming and parallel execution, discuss about Python built-ins concurrent programming mechanisms and the pitfalls of multi-threading in Python.
Understanding Concurrent Programming vs Parallel Execution
Concurrent programming is not equivalent to parallel execution, despite the fact that these two terms are often being used interchangeably.
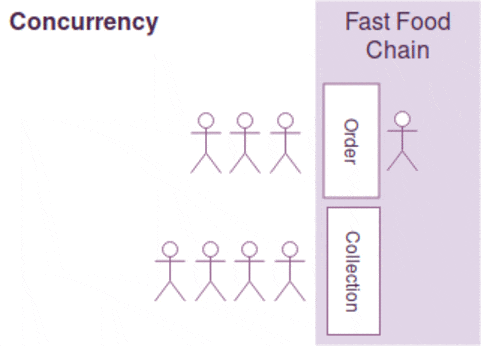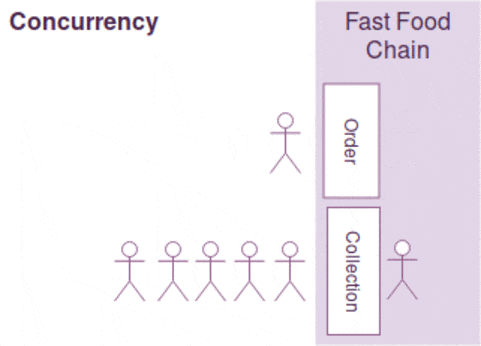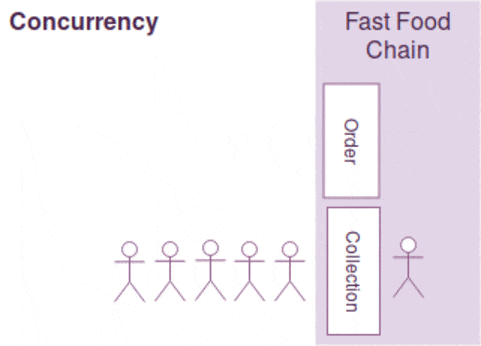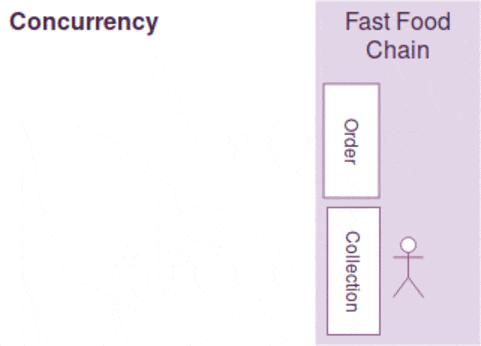 Concurrency is a property which more than one operation can be run simultaneously but it doesn't mean it will be. (Imagine if your processor is single-threaded. )
Concurrency is a property which more than one operation can be run simultaneously but it doesn't mean it will be. (Imagine if your processor is single-threaded. )
 Parallel is a property which operations are actually being run simultaneously. It is usually determined by the hardware constraints.
Parallel is a property which operations are actually being run simultaneously. It is usually determined by the hardware constraints.
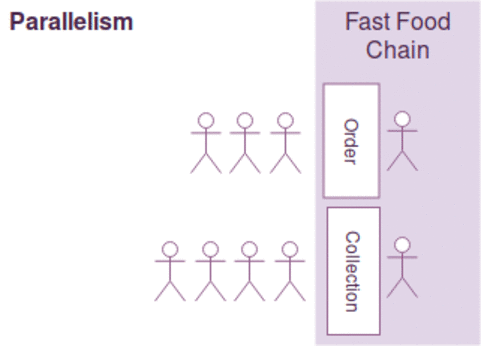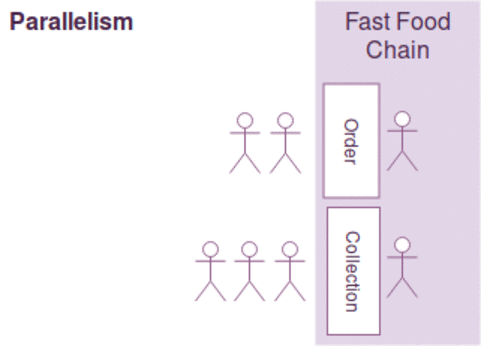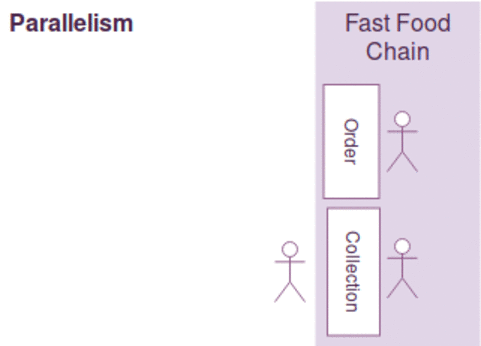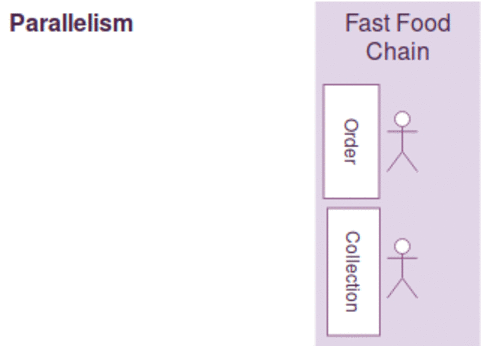
Think of your program as a fast food chain, concurrency is incorporated when two separate counters for order and collection are built. However, it doesn't ensure parallelism as it depends on the number of employees available. If there is only one employee to handle both order and collection requests, the operations can't be running in parallel. Parallelism is only present when there are two employees to serve order and collection simultaneously.
Python Built-ins
Now, what do we have in Python? Does Python have built-ins that facilitate us to build concurrent programs and enable them to run in parallel?
In the following discussion, we assume our programs are all written and run in a multi-threaded or multi-core processor.
The answer is Jein (Yes and No in German). Why yes? Python does have built-in libraries for the most common concurrent programming constructs - multiprocessing and multithreading. You may think, since Python supports both, why Jein? The reason is, multithreading in Python is not really multithreading, due to the GIL in Python.
Multi-threading - Thread-based Parallelism
threading is the package that provides API to create and manage threads. Threads in Python are always non-deterministic and their scheduling is performed by the operating system. However, multi-threading might not be doing what you expect to be.
Why multi-threading in Python might not be what you want?
Other than the common pitfalls such as deadlock, starvation in multithreading in general. Python is notorious for its poor performance in multithreading.
Let us look at the following snippet:
import threading
def countdown():
x = 1000000000
while x > 0:
x -= 1
# Implementation 1: Multi-threading
def implementation_1():
thread_1 = threading.Thread(target=countdown)
thread_2 = threading.Thread(target=countdown)
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
# Implementation 2: Run in serial
def implementation_2():
countdown()
countdown()
Which implementation would be faster? Let us perform a timing.
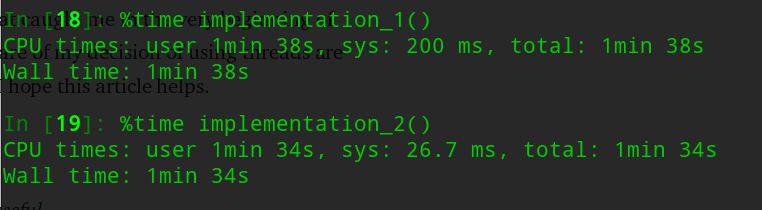 Surprisingly, running 2
Surprisingly, running 2 countdown() serially outperformed multi-threading? How could this happen? Thanks to the notorious Global Interpreter Lock (GIL).
What is Global Interpreter Lock (GIL)?
Depends on the distribution of your Python, which most of the case, is an implementation of CPython. CPython is the original implementation of Python, you can read more about it in this StackOverflow thread.
In CPython, multi-threading is supported by introducing a Mutex known as Global Interpreter Lock (aka GIL). It is to prevent multiple threads from accessing the same Python object simultaneously. This make sense, you wouldn't want someone else to mutate your object while you are processing it.
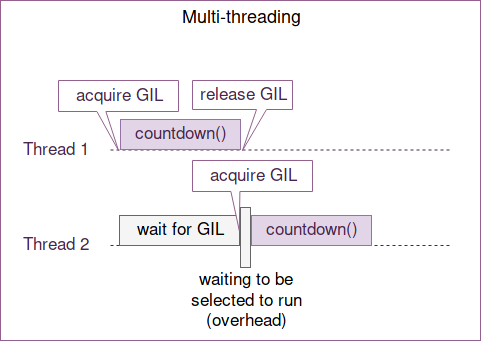 So, from our code snippet above,
So, from our code snippet above, implementation_1 creates 2 threads and are supposed to run in parallel on a multi-threaded system. However, only one thread can hold the GIL at a time, one thread must wait for another thread to release the GIL before running. Meanwhile, scheduling and switching done by the OS introduce overhead that make implementation_1 even slower.
How to bypass GIL?
How could we bypass GIL, while maintaining the use of multi-threading? There is no universal good answer for this question, as this varies from the purpose of your code.
Using a different implementation of Python such as Jython, PyPy or IronPython is an option. I personally do not advocate using a different implementation of Python since most libraries written are not tested against different implementations of Python.
Another potential workaround is to use C-extenstion, or better known as Cython. Note that Cython and CPython are not the same. You can read more about Cython here.
Use multiprocessing instead. Since in multiprocessing, an interpreter is created for every child process. The situation where threads fighting for GIL simple doesn't exist as there is always only a main thread in every process.
Despite all the pitfalls, should we still use multi-threading?
If your task is I/O bound, meaning that the thread spends most of its time handling I/O such as performing network requests. It is still perfectly fine to use multi-threading as the thread is, most of the time, being blocked and put into blocked queue by the OS. Thread is also always less resource-hungry than process.
Multiprocessing - Process-based Parallelism
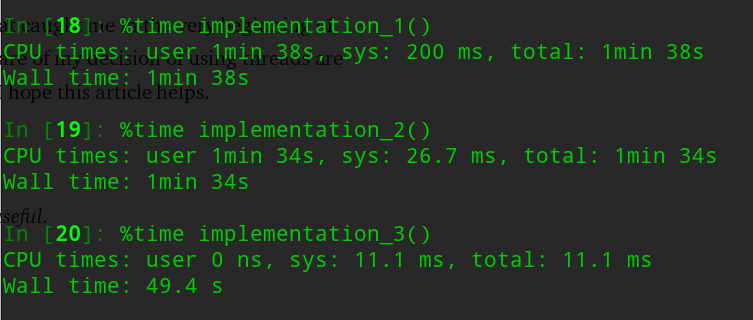
Let us implement our previous code snippet using multiprocessing.
import multiprocessing
# countdown() is defined in the previous snippet.
def implementation_3():
process_1 = multiprocessing.Process(target=countdown)
process_2 = multiprocessing.Process(target=countdown)
process_1.start()
process_2.start()
process_1.join()
process_2.join()
The result itself is self-explanatory.
Conclusion
The constraint of GIL was something that caught me in the very beginning of time as a Python developer. I wasn't aware of my decision of using threads is totally worthless until I did the timing. I hope this article helps.