



Nowadays we hear the term "Machine Learning" a lot usually for predicting analysis and artificial intelligence. but machine learning has actually been a field of its own for several decades. we are taking it's advantage in a wide form only now. so thanks to modern advancement in computing power. Now the question is how this machine learning actually work?? It's answer should be algorithm.
Machine learning is a form of artificial intelligence (AI) that teaches computers to think in a similar way to how humans do. Currently, machine learning has been used in multiple fields and industries. It works by exploring data and identifying patterns, and involves minimal human intervention. For example, medical diagnosis, learning association, image processing, prediction, regression , classification etc. The intelligent systems built on machine learning algorithms have the capability to learn from past experience or historical data.
The purpose of machine learning is to discover patterns in your data and then make predictions based on often complex patterns to answer business questions, detect and analyze trends and help solve problems. Machine intelligence enables complex and larger data to be processed and analyzed along with the desired results being achieved such as determining customer trends, detecting fraud, spotting buying trends and other primary objectives.
We can input here some basics ideas and concepts of machine learning that will help us to understand it more clear and easy.
1. Supervised and Unsupervised machine learning:Supervised learning and Unsupervised learning are actually two types of Machine learning. but first one is prediction with human intervention and the second one is not. The main use of supervised learning is to predict future on the basis of behavior, nature and history data. we can make research on a special field which is called target field by using supervised learning algorithm of related field. In that case we can use some tags as a behavior. for example spamming emails. Machine learning put our emails into spam by seeing some specific tags which we use as a behavior to train our system in order to complete the task. On the other hand, unsupervised learning uses historical data that has no target field. The aim is to explore the data and find some structure or to organize it. For example, it is often used to group customers with characteristics or behaviors similar to those of highly segmented marketing campaigns.
2.Regression and Classification: There are two topics to understand in Supervised learning. These are regression and classification where regression predicts a number but classification system predicts a category. The example for regression is to predict the price of an item or the number of reservations that will be made in a train etc. On the other hand we can say spam email is an example of classification.
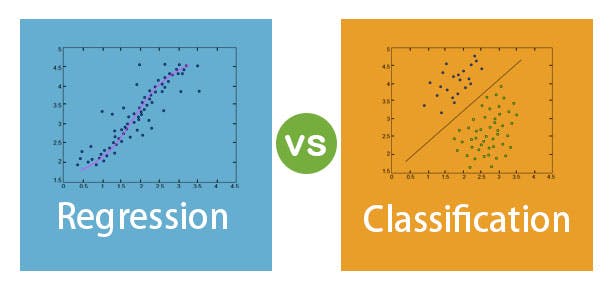
The primary difference between classification and regression decision trees is that, the classification decision trees are built with unordered values with dependent variables. The regression decision trees take ordered values with continuous values.
3. Data Mining: It is rare to see how data mining and machine learning concepts are connected to each other. but these are strongly related concepts. It is a process of extracting and discovering patterns in large data sets involving methods by using machine learning, statistics, and database systems. In short, it could be said that data mining has an exploratory function while machine learning focuses on prediction.
4. Training:Training is a process where we detect the pattern of a dataset that it is the main part of machine learning. It requires some human involvement to analyze or process the data for machine learning use.
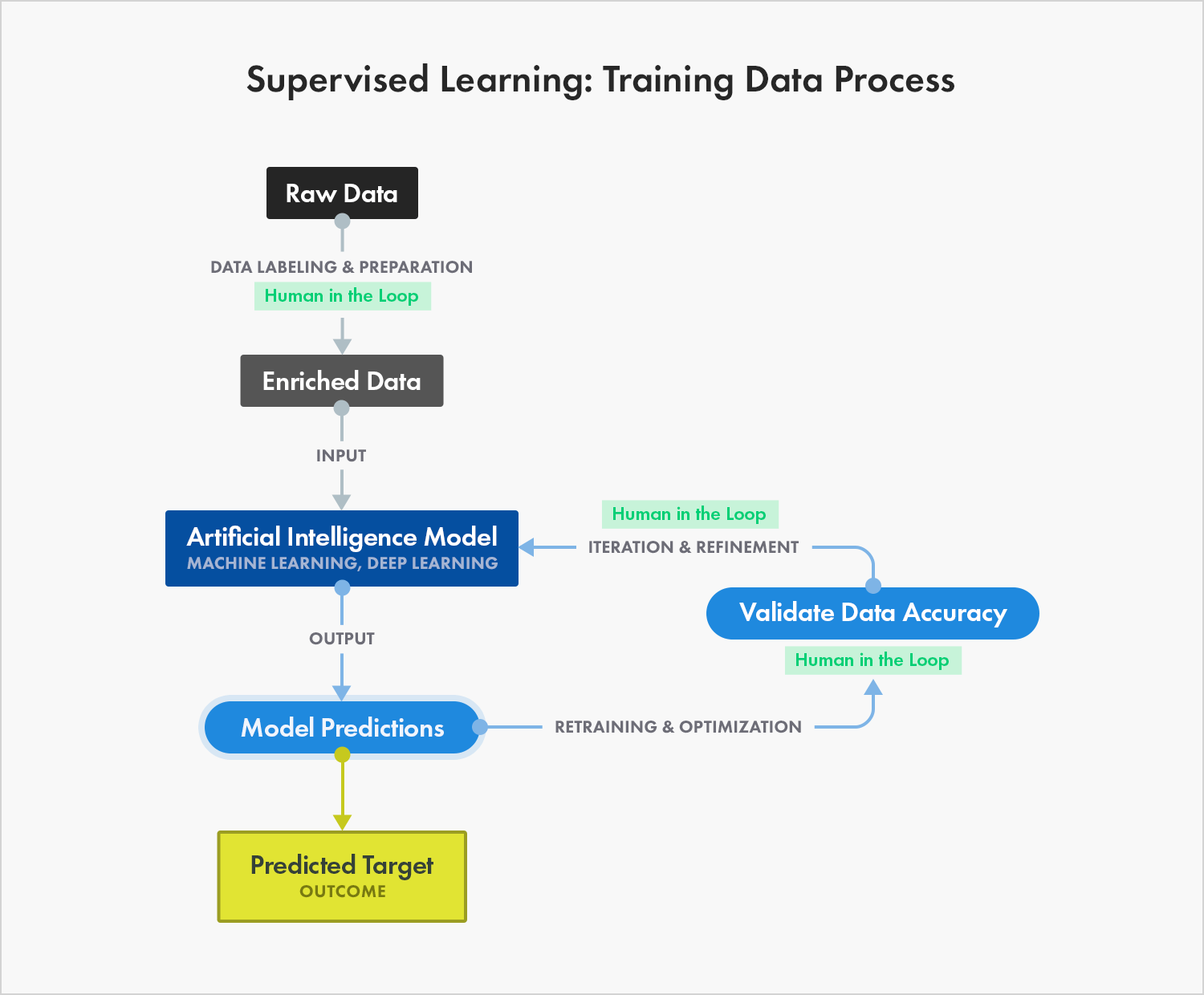
5. Dataset:It is the raw material of the prediction system. This is the historical data used to train the system that detects patterns. The dataset is composed of instances, and instances of factors, characteristics or properties.
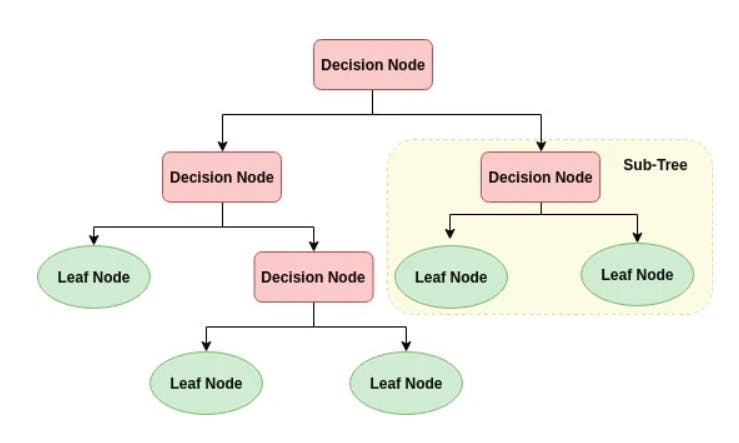
6. Decision tree:It is the skeleton of the prediction model that is usually represented graphically as a tree, in which the branches are the recognized patterns in the learning process. Predictions for each pattern would be placed on the leaves of the branches.
Conclusion We’ve covered much of the basic theory underlying the field of Machine Learning here, but of course, we have only barely scratched the surface. Keep in mind that to really apply the theories contained in this introduction to real life machine learning examples, a much deeper understanding of the topics discussed herein is necessary. There are many subtleties and pitfalls in ML, and many ways to be lead astray by what appears to be a perfectly well-tuned thinking machine. Almost every part of the basic theory can be played with and altered endlessly, and the results are often fascinating. Many grow into whole new fields of study that are better suited to particular problems.