


Regular expressions (or regex in short) is a much-hated & underrated topic so far with Modern C++. But at the same time, correct use of regex can spare you writing many lines of code. If you have spent quite enough time in the industry. And not knowing regex then you are missing out on 20-30% productivity. In that case, I highly recommend you to learn regex, as it is one-time investment(something similar to learn once, write anywhere philosophy).
/!\\: This article has been originally published on my blog. If you are interested in receiving my latest articles, please sign up to my newsletter.
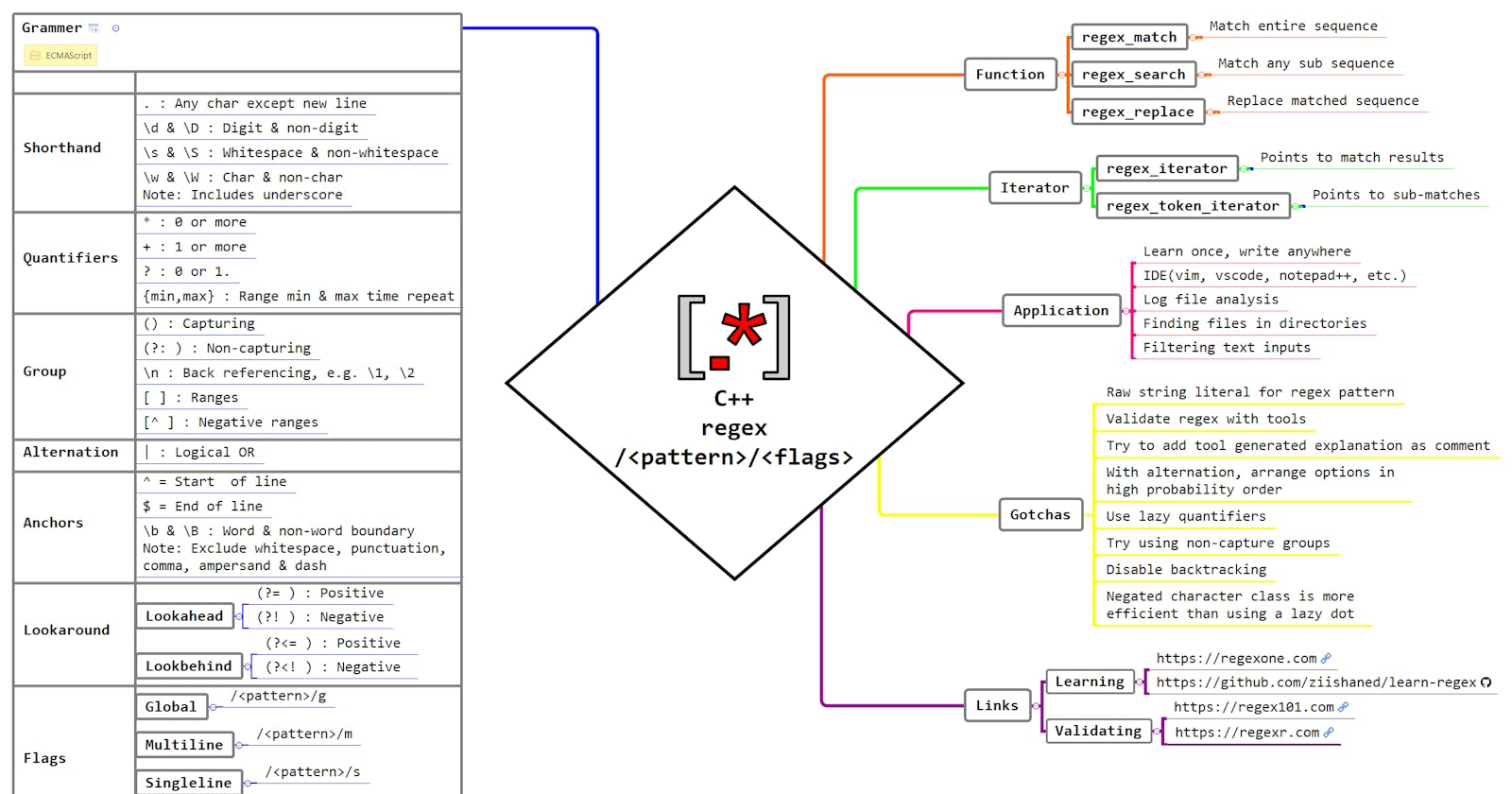
Initially, In this article, I have decided to include regex-in-general also. But it doesn't make sense, as there is already people/tutorial out there who does better than me in teaching regex. But still, I left a small section to address Motivation & Learning Regex. For the rest of the article, I will be focusing on functionality provided by C++ to work with regex. And if you are already aware of regex, you can use the above mind-map as a refresher.
Pointer: The C++ standard library offers several different "flavours" of regex syntax, but the default flavour (the one you should always use & I am demonstrating here) was borrowed wholesale from the standard for ECMAScript.
Motivation
- I know its pathetic and somewhat confusing tool-set. Consider the below regex pattern for an example that extract time in 24-hour format i.e. HH:MM.
\b([01]?[0-9]|2[0-3]):([0-5]\d)\b
- I mean! Who wants to work with this cryptic text?
- And whatever running in your mind is 100% reasonable. In fact, I have procrastinated learning regex twice due to the same reason. But, believe me, all the ugly looking things are not that bad.
- The way(↓) I am describing here won't take more than 2-3 hours to learn regex that too intuitively. And After learning it you will see the compounding effect with return on investment over-the-time.
Learning Regex
- Do not google much & try to analyse which tutorial is best. In fact, don't waste time in such analysis. Because there is no point in doing so. At this point in time(well! if you don't know the regex) what really matters is "Getting Started" rather than "What Is Best!".
- Just go to https://regexone.com without much overthinking. And complete all the lessons. Trust me here, I have explored many articles, courses(<=this one is free, BTW) & books. But this is best among all for getting started without losing motivation.
- And after it, if you still have an appetite to solve more problem & exercises. Consider the below links:
std::regex & std::regex_error Example
int main() {
try {
static const auto r = std::regex(R"(\)"); // Escape sequence error
} catch (const std::regex_error &e) {
assert(strcmp(e.what(), "Unexpected end of regex when escaping.") == 0);
assert(e.code() == std::regex_constants::error_escape);
}
return EXIT_SUCCESS;
}
- You see! I am using raw string literals. You can also use the normal string. But, in that case, you have to use a double backslash for an escape sequence.
- The current implementation of
std::regexis slow(as it needs regex interpretation & data structure creation at runtime), bloated and unavoidably require heap allocation(not allocator-aware). So, beware if you are usingstd::regexin a loop(see C++ Weekly -- Ep 74 -- std::regex optimize by Jason Turner). Also, there is only a single member function that I think could be of use is std::regex::mark_count() which returns a number of capture groups. - Moreover, if you are using multiple strings to create a regex pattern at run time. Then you may need exception handling i.e.
std::regex_errorto validate its correctness.
std::regex_search Example
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"((\w+):(\w+);)");
smatch m;
if (regex_search(input, m, r)) {
assert(m.size() == 3);
assert(m[0].str() == "PQR:2;"); // Entire match
assert(m[1].str() == "PQR"); // Substring that matches 1st group
assert(m[2].str() == "2"); // Substring that matches 2nd group
assert(m.prefix().str() == "ABC:1-> "); // All before 1st character match
assert(m.suffix().str() == ";; XYZ:3<<<"); // All after last character match
// for (string &&str : m) { // Alternatively. You can also do
// cout << str << endl;
// }
}
return EXIT_SUCCESS;
}
smatchis the specializations of std::match_results that stores the information about matches to be retrieved.
std::regex_match Example
- Short & sweet example that you may always find in every regex book is email validation. And that is where our
std::regex_matchfunction fits perfectly.
bool is_valid_email_id(string_view str) {
static const regex r(R"(\w+@\w+\.(?:com|in))");
return regex_match(str.data(), r);
}
int main() {
assert(is_valid_email_id("vishalchovatiya@ymail.com") == true);
assert(is_valid_email_id("@abc.com") == false);
return EXIT_SUCCESS;
}
- I know this is not full proof email validator regex pattern. But my intention is also not that.
- Rather you should wonder why I have used
std::regex_match! notstd::regex_search! The rationale is simplestd::regex_matchmatches the whole input sequence. - Also, Noticeable thing is static regex object to avoid constructing ("compiling/interpreting") a new regex object every time the function entered.
- The irony of above tiny code snippet is that it produces around 30k lines of assembly that too with
-O3flag. And that is ridiculous. But don't worry this is already been brought to the ISO C++ community. And soon we may get some updates. Meanwhile, we do have other alternatives (mentioned at the end of this article).
Difference Between std::regex_match & std::regex_search?
- You might be wondering why do we have two functions doing almost the same work? Even I had the doubt initially. But, after reading the description provided by cppreference over and over. I found the answer. And to explain that answer, I have created the example(obviously with the help of StackOverflow):
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"((\w+):(\w+);)");
smatch m;
assert(regex_match(input, m, r) == false);
assert(regex_search(input, m, r) == true && m.ready() == true && m[1] == "PQR");
return EXIT_SUCCESS;
}
std::regex_matchonly returnstruewhen the entire input sequence has been matched, whilestd::regex_searchwill succeed even if only a sub-sequence matches the regex.
std::regex_iterator Example
std::regex_iteratoris helpful when you need very detailed information about matched & sub-matches.
#define C_ALL(X) cbegin(X), cend(X)
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"((\w+):(\d))");
const vector<smatch> matches{
sregex_iterator{C_ALL(input), r},
sregex_iterator{}
};
assert(matches[0].str(0) == "ABC:1"
&& matches[0].str(1) == "ABC"
&& matches[0].str(2) == "1");
assert(matches[1].str(0) == "PQR:2"
&& matches[1].str(1) == "PQR"
&& matches[1].str(2) == "2");
assert(matches[2].str(0) == "XYZ:3"
&& matches[2].str(1) == "XYZ"
&& matches[2].str(2) == "3");
return EXIT_SUCCESS;
}
- Earlier(in C++11), there was a limitation that using
std::regex_interatoris not allowed to be called with a temporary regex object. Which has been rectified with overload from C++14.
std::regex_token_iterator Example
std::regex_token_iteratoris the utility you are going to use 80% of the time. It has a slight variation as compared tostd::regex_iterator. The difference betweenstd::regex_iterator&std::regex_token_iteratorisstd::regex_iteratorpoints to match results.std::regex_token_iteratorpoints to sub-matches.
- In
std::regex_token_iterator, each iterator contains only a single matched result.
#define C_ALL(X) cbegin(X), cend(X)
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"((\w+):(\d))");
// Note: vector<string> here, unlike vector<smatch> as in std::regex_iterator
const vector<string> full_match{
sregex_token_iterator{C_ALL(input), r, 0}, // Mark `0` here i.e. whole regex match
sregex_token_iterator{}
};
assert((full_match == decltype(full_match){"ABC:1", "PQR:2", "XYZ:3"}));
const vector<string> cptr_grp_1st{
sregex_token_iterator{C_ALL(input), r, 1}, // Mark `1` here i.e. 1st capture group
sregex_token_iterator{}
};
assert((cptr_grp_1st == decltype(cptr_grp_1st){"ABC", "PQR", "XYZ"}));
const vector<string> cptr_grp_2nd{
sregex_token_iterator{C_ALL(input), r, 2}, // Mark `2` here i.e. 2nd capture group
sregex_token_iterator{}
};
assert((cptr_grp_2nd == decltype(cptr_grp_2nd){"1", "2", "3"}));
return EXIT_SUCCESS;
}
Inverted Match With std::regex_token_iterator
#define C_ALL(X) cbegin(X), cend(X)
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"((\w+):(\d))");
const vector<string> inverted{
sregex_token_iterator{C_ALL(input), r, -1}, // `-1` = parts that are not matched
sregex_token_iterator{}
};
assert((inverted == decltype(inverted){
"",
"-> ",
";;; ",
"<<<",
}));
return EXIT_SUCCESS;
}
std::regex_replace Example
string transform_pair(string_view text, regex_constants::match_flag_type f = {}) {
static const auto r = regex(R"((\w+):(\d))");
return regex_replace(text.data(), r, "$2", f);
}
int main() {
assert(transform_pair("ABC:1, PQR:2"s) == "1, 2"s);
// Things that aren't matched are not copied
assert(transform_pair("ABC:1, PQR:2"s, regex_constants::format_no_copy) == "12"s);
return EXIT_SUCCESS;
}
- You see in 2nd call of transform_pair, we passed flag
std::regex_constants::format_no_copywhich suggest do not copy thing that isn't matched. There are many such useful flags under std::regex_constant. - Also, we have constructed the fresh string holding the results. But what if we do not want a new string. Rather wants to append the results directly to somewhere(probably container or stream or already existing string). Guess what! the standard library has covered this also with overloaded
std::regex_replaceas follows:
int main() {
const string input = "ABC:1-> PQR:2;;; XYZ:3<<<"s;
const regex r(R"(-|>|<|;| )");
// Prints "ABC:1 PQR:2 XYZ:3 "
regex_replace(ostreambuf_iterator<char>(cout), C_ALL(input), r, " ");
return EXIT_SUCCESS;
}
Use Cases
Splitting a String With Delimiter
- Although
std::strtokis best suitable & optimal candidate for such a task. But just to demonstrate how you can do it with regex:
#define C_ALL(X) cbegin(X), cend(X)
vector<string> split(const string& str, string_view pattern) {
const auto r = regex(pattern.data());
return vector<string>{
sregex_token_iterator(C_ALL(str), r, -1),
sregex_token_iterator()
};
}
int main() {
assert((split("/root/home/vishal", "/")
== vector<string>{"", "root", "home", "vishal"}));
return EXIT_SUCCESS;
}
Trim Whitespace From a String
string trim(string_view text) {
static const auto r = regex(R"(\s+)");
return regex_replace(text.data(), r, "");
}
int main() {
assert(trim("12 3 4 5"s) == "12345"s);
return EXIT_SUCCESS;
}
Finding Lines Containing or Not Containing Certain Words From a File
string join(const vector<string>& words, const string& delimiter) {
return accumulate(next(begin(words)), end(words), words[0],
[&delimiter](string& p, const string& word)
{
return p + delimiter + word;
});
}
vector<string> lines_containing(const string& file, const vector<string>& words) {
auto prefix = "^.*?\\b("s;
auto suffix = ")\\b.*$"s;
// ^.*?\b(one|two|three)\b.*$
const auto pattern = move(prefix) + join(words, "|") + move(suffix);
ifstream infile(file);
vector<string> result;
for (string line; getline(infile, line);) {
if(regex_match(line, regex(pattern))) {
result.emplace_back(move(line));
}
}
return result;
}
int main() {
assert((lines_containing("test.txt", {"one","two"})
== vector<string>{"This is one",
"This is two"}));
return EXIT_SUCCESS;
}
/* test.txt
This is one
This is two
This is three
This is four
*/
- Same goes for finding lines that are not containing words with the pattern
^((?!(one|two|three)).)*$.
Finding Files in a Directory
namespace fs = std::filesystem;
vector<fs::directory_entry> find_files(const fs::path &path, string_view rg) {
vector<fs::directory_entry> result;
regex r(rg.data());
copy_if(
fs::recursive_directory_iterator(path),
fs::recursive_directory_iterator(),
back_inserter(result),
[&r](const fs::directory_entry &entry) {
return fs::is_regular_file(entry.path()) &&
regex_match(entry.path().filename().string(), r);
});
return result;
}
int main() {
const auto dir = fs::temp_directory_path();
const auto pattern = R"(\w+\.png)";
const auto result = find_files(fs::current_path(), pattern);
for (const auto &entry : result) {
cout << entry.path().string() << endl;
}
return EXIT_SUCCESS;
}
Tips For Using Regex-In-General
- Use raw string literal for describing the regex pattern in C++.
- Use the regex validating tool like https://regex101.com. What I like about regex101 is code generation & time-taken(will be helpful when optimizing regex) feature.
- Also, try to add generated explanation from validation tool as a comment exactly above the regex pattern in your code.
- Performance:
- If you are using alternation, try to arrange options in high probability order like
com|net|org. - Try to use lazy quantifiers if possible.
- Use non-capture groups wherever possible.
- Disable Backtracking.
- Using the negated character class is more efficient than using a lazy dot.
- If you are using alternation, try to arrange options in high probability order like
Parting Words
It's not just that you will use regex with only C++ or any other language. I myself use it mostly on IDE(in vscode to analyse log files) & on Linux terminal. But, bear in mind that overusing regex gives the feel of cleverness. And, it's a great way to make your co-workers (and anyone else who needs to work with your code) very angry with you. Also, regex is overkill for most parsing tasks that you'll face in your daily work.
The regexes really shine for complicated tasks where hand-written parsing code would be just as slow anyway; and for extremely simple tasks where the readability and robustness of regular expressions outweigh their performance costs.
One more notable thing is current regex implementation(till 19th June 2020) in standard libraries have performance & code bloating issues. So choose wisely between Boost, CTRE and Standard library versions. Most probably you might go with the Hana Dusíková's work on Compile Time Regular Expression. Also, her CppCon talk from 2018 & 2019's would be helpful especially if you plan to use regex in embedded systems.