



What is the problem to solve?
A problem well-stated is Half-solved
The challenge was laid out by “No Silver Bullet — Essence and Accident in Software Engineering”
And “Out of the Tar Pit” elaborated the problem statement, and contributed a possible solution.
I don’t think debating what is essential state, what is accidental state is helpful. But it is clear, the problem is about STATE
The problem to solve is always the same. It is the big elephant in the room all the time. Imperative programming to manage state is too hard.
What is the problem of imperative programming?
We can update those states, quite easily actually. Imperative programming is straightforward, it gets things done. Just put together a bunch of CPU instructions to update state, and CPU will do it. The software execution can be drawn as this naive diagram
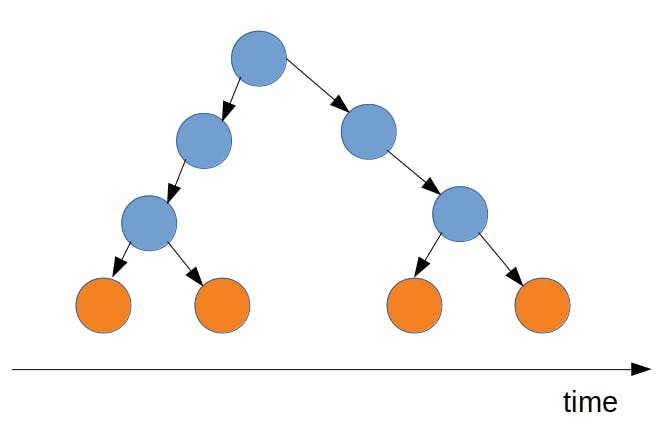
The external behavior of a software is essentially a ordered series of state update (yellow circles in the diagram). However, the problem is:
Describe this sequence of state update literally with one to one mapping, will lead to code that is "lengthy", "tedious", "fragmented".
The most straightforward way, the easist way, is not the best way. Even if, we extracted out lots of nice functions (those blue circles), the code might looks tidier, but still “lengthy”, “tedious”, “fragmented”. Readability is a subjective. “Simple Made Easy” suggests “Simple” is objective. I will define simple as following measurable properties:
- Fewer states: the number of states, smaller is better
- Sequential: if we have to deal with time ordered state update, let it be sequential
- Isolated: state update is already hard enough to reason about. If they are not isolated, we have to pull all of them in my working memory to think about them all in once.
- Continuous: this line and next line, they are put so close together because they are causally related. On the other thand, if two state update are causally related, they should be put as close as possible.
The goal is not to have zero states, but fewer the better. Then we keep the code sequential/continous/isolated to keep the complexity of state updating code on check. The opposite of those four properties are:
- Excessively stateful: many many states, even unnecessary (or accidental state as described in out of tar pit paper)
- Concurrent or Parallel: threads or coroutines, they are complex.
- Entangled: we have to ignore the fact they are components, to reason about them or to optimize them as a big entangled mess.
- Long range causality: the application logic is fragmented, connected via a global state called database
The goal is not to eliminate all states, but to keep them as few as possible. There will always be essential states that we have to manage and update with logic in order, that is what business process is all about after all. Even TLA+ evolved as PlusCal looks a lot like a imperative program. Imperative style is still the best known form to express temporal logic for human comprehension. But we have to keep it simple, by keeping it sequential, continuous and isolated.
What about OOP/DDD?
Using object to encapsulate state is a big part of OOP or DDD in particular. DDD in practices boils down to three steps:
- Application service load back the domain model from database
- Use aggregate root to encapsulate all the changes
- The side-effect is in the form of modified domain model or issued new domain events. Application service save the models and publishes the events
The core idea is “Aggregate Root” can be a black box, nothing can by pass it, that will make our state update code encapsulated in one place. But there are two issues:
- The method on aggregate root, is not very different from a free function taking the aggregate root as first argument. OOP is just ordinal imperative programming.
- The interaction between objects, especially for the business process involving multiple domain concepts. It is hard to decide which aggregate root is the real aggregate root, which should take care of the process. Or put in another way, business process as a function in essence, itself should be the aggregate root.
We can re-examine the four properties above
- Fewer states: as long as the state has to be updated manually in the temporal manner, they are still there
- Sequential: still need thread or coroutine to exploit new hardware.
- Isolated: domain model isolates the states, but to optimize the data loading, we have to load them in bigger batch to avoid 1+N too many SQL problem.
- Continuous: the business logic is scatter around. It tends to be less continuous, not more continuous, compared to raw imperative programming.
What about pure functional?
In “Out of the Tar Pit”, author proposed a style of programming called Functional Relation Programming. It is known as event sourcing in DDD community. I agree, the event (user input) is the only true essential state, everything else can be derived from it, so accidental. But projecting every state from event is not as “easy” as temporal logic expressed by imperative programming. As Rich Hickey suggested, “easy” is subjective. But we can not ignore the fact most people is not familiar with this style, because it is detached from our primary familiarity source, the physical real world.
The physical world do not store the state as a ledger of events. The god does not derivative your height and weight from the food you have eaten since you have born. We make decision according to the situation. It is just the matter we load the situation from a mutable state, or we derivative the situation from the history on demand in memory. Reasoning based on current state for future, coupled with calculating the current state, will complicate the logic.
The approach is still not popular after all these years. We are presenting an alternative approach to manage state, which might be more familiar and practical.
Simpler State Management
The goal is to make it simple
- Fewer states: if one state is not necessary eliminate it. If one state can be derived from other state, make it declarative.
- Make imperative programming sequential / isolated / continuous
The code is written in TypeScript, but need a special runtime to make it working. You can think it is a new language, with identical syntax with TypeScript.
Fewer states by UI binding
UI binding is mainstream now. This demo looks like this:
The UI is powered by Web DOM, it is a separate state. Using binding like this we can make it a derived state:
<Button @onClick="onMinusClick">-</Button>
<span margin="8px">{{ value }}</span>
<Button @onClick="onPlusClick">+</Button>
The data bind to:
export class CounterDemo extends RootSectionModel {
value = 0;
onMinusClick() {
this.value -= 1;
}
onPlusClick() {
this.value += 1;
}
}
But why binding is eliminating state? Compare code written in these two styles. First, we update these two states in order
// update state in temporal order
this.value -= 1;
this.updateView({msg: this.value})
Second, we bind the two state, then update the model
// setup the binding in advance
<span margin="8px">{{ value }}</span>
// then update the state
this.value -= 1
The difference is, binding or any declarative style programming, setup the relationship which is true, out of context. This can remove the derived state from temporal reasoning and description. The fewer states need to manually maintained within the time arrow, the better.
Fewer states by even more binding
If binding can remove state from temporal logic, we need more. Let’s layout all the states within the system:
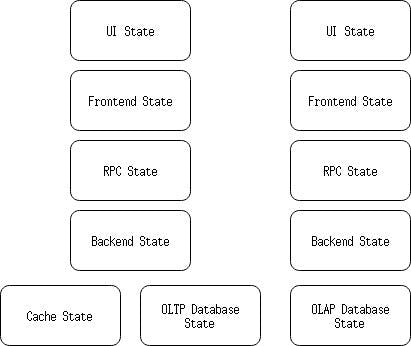
Binding UI state to Frontend state only solved a tiny bit of the problem. Who will manage the Frontend state then? We need to question every single state, can we eliminate it? Or, can we derive it from another state? There is obvious quick win here. When presenting the UI, it loads the data from database, all the way up to UI. There might be some transformation, but can be conveniently described as data binding as well. Given this simple application:
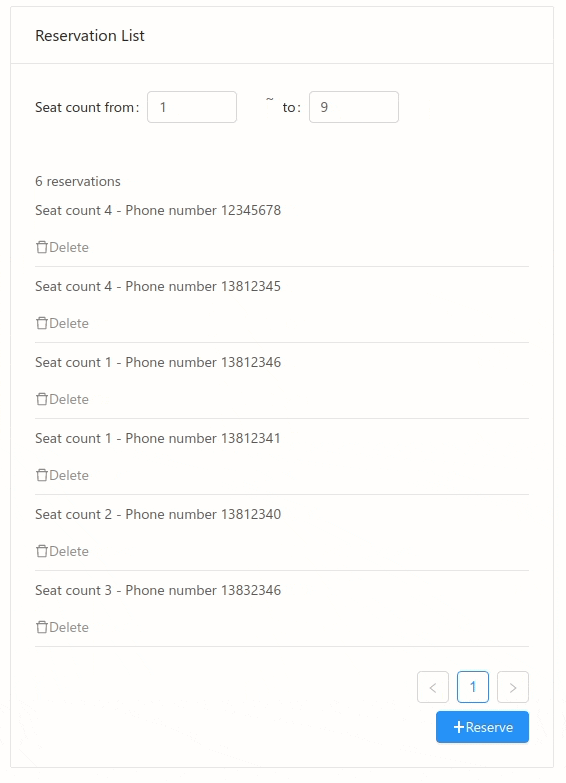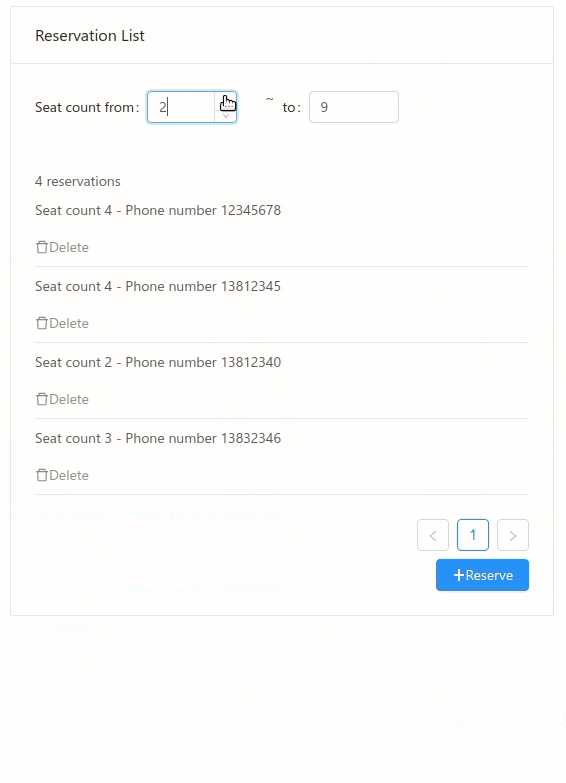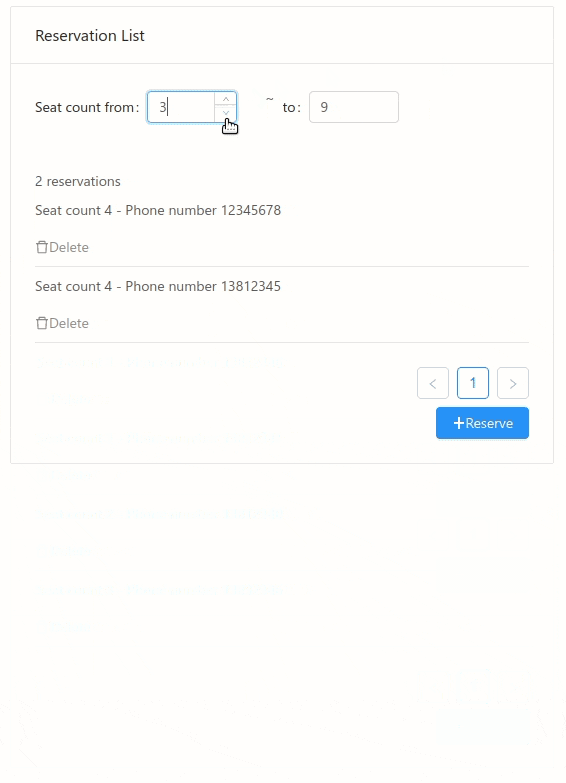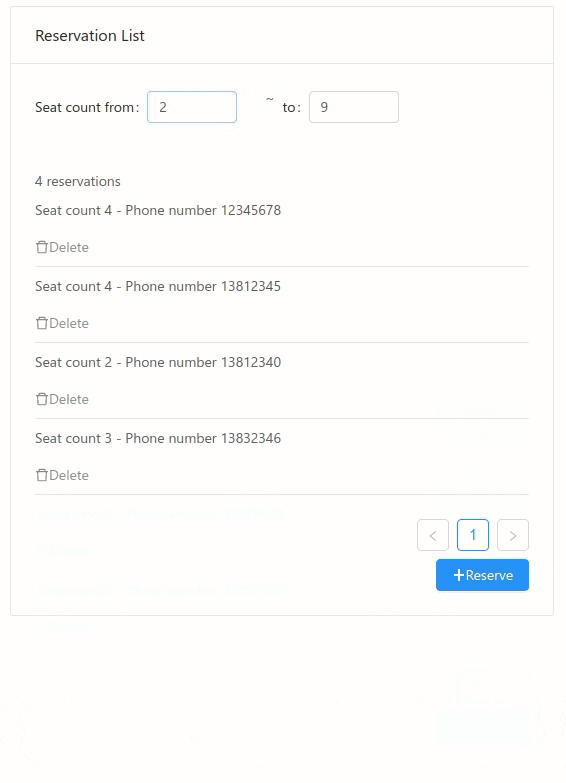
It is just a simple list view, to show some data loaded from database. We can bind the UI directly to some database query:
ListDemo.xml
<Card title="Reservation List" margin="16px">
<Form layout="inline">
<InputNumber :value="&from" label="Seat count from" />
<span margin="8px"> ~ </span>
<InputNumber :value="&to" label="to" />
</Form>
<span>Total: {{ totalCount }} reservations</span>
<List :dataSource="filteredReservations" itemLayout="vertical" size="small">
<json #pagination>
{ "pageSize": 10 }
</json>
<slot #element="::element">
<ShowReservation :reservation="element.item">
</slot>
</List>
<Row justifyContent="flex-end" marginTop="8px">
<Button type="primary" icon="plus" @onClick="onNewReservationClick">Reserve</Button>
</Row>
</Card>
the model bind to ListDemo.ts
export class ListDemo extends RootSectionModel {
public from: number = 1;
public to: number = 9;
public get filteredReservations() {
return this.scene.query(Reservation_SeatInRange, { from: this.from, to: this.to });
}
public get totalCount() {
return this.filteredReservations.length;
}
}
the domain model Reservation.ts
@sources.Mysql()
export class Reservation extends Entity {
public seatCount: number;
public phoneNumber: string;
}
@where('seatCount >= :from AND seatCount <= :to')
export class Reservation_SeatInRange {
public static SubsetOf = Reservation;
public from: number;
public to: number;
}
When "from" or "to" changed, the "filteredReservations" will be updated, and the "totalCount" will also be updated, and the UI will be re-rendered with latest value. Binding to database, eliminate a lot of intermediate state between the UI and DB.
Fewer states by tight coupling
Frontend and backend work together to provide a user interface for the human to interact with. They should be tightly coupled.
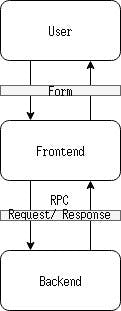
If the RPC interface is dedicated for the service of the functionality provided by the form, why not merge the two states? Then it become a shared whiteboard between user/frontend/backend:
Take this application for example:
We can share the form state, with both frontend and backend. Here is the code:
FormDemo.xml
<Card title="New reservation" width="360px" margin="24px">
<Form>
{{ message }}
<Input :value="&phoneNumber" label="Phone number" />
<InputNumber :value="&seatCount" label="Seat count" />
<Button @onClick="onReserveClick">Reserve</Button>
</Form>
</Card>
FormDemo.ts
@sources.Scene
export class FormDemo extends RootSectionModel {
@constraint.min(1)
public seatCount: number;
@constraint.required
public phoneNumber: string;
public message: string = '';
public onBegin() {
this.reset();
}
public onReserveClick() {
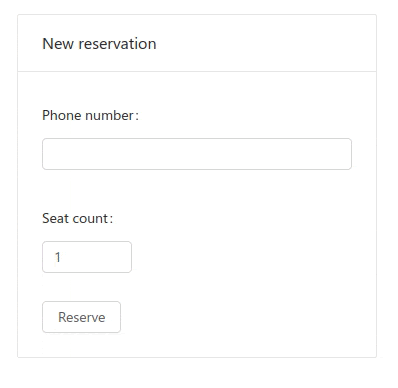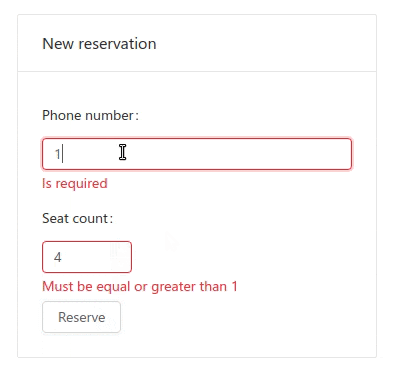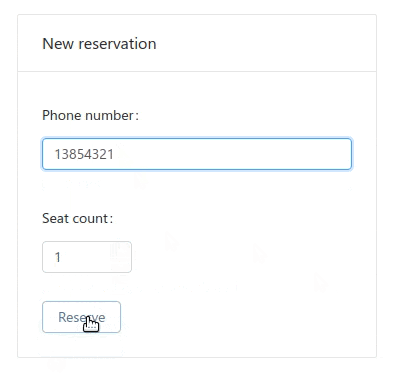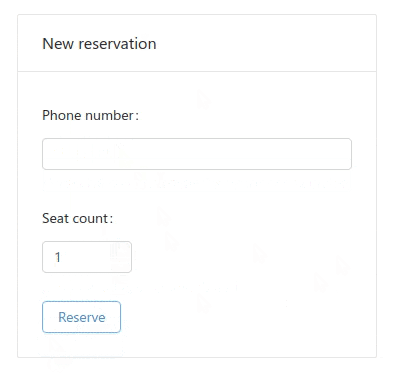
if (constraint.validate(this)) {
return;
}
this.saveReservation();
setTimeout(this.clearMessage.bind(this), 1000);
}
@command({ runAt: 'server' })
private saveReservation() {
if (constraint.validate(this)) {
return;
}
const reservation = this.scene.add(Reservation, this);
try {
this.scene.commit();
} catch (e) {
const existingReservations = this.scene.query(Reservation, { phoneNumber: this.phoneNumber });
if (existingReservations.length > 0) {
this.scene.unload(reservation);
constraint.reportViolation(this, 'phoneNumber', {
message: 'Can only have one reservation per phone number',
});
return;
}
throw e;
}
this.reset();
this.message = 'Reserved successfully';
}
private reset() {
this.seatCount = 1;
this.phoneNumber = '';
}
private clearMessage() {
this.message = '';
}
}
The method saveReservation is marked with "runAt: server". The form state will be sent to backend for calculation, and then the form state updated in the backend will be rendered back to the UI. Although this is unconventional, but with fewer states, the code should be easier to reason about in theory.
This concludes the first part, we have seen following ways to reduce states count:
- Derived state: such as computed property, autorun state subscription, database view, materialized view
- Bind the database query, use it as if it is local state
- Share form between frontend and backend
Simpler Temporal Logic
Declarative style data binding can remove some non-essential state from the system. Now, we need to focus on the temporal logic itself. The first property is sequential.
Sequential
Sequential single thread programming is simple. Yet, CPU tried very hard to parallelize the execution of the single threaded instruction stream. It will look ahead and speculate, as long as there is no data dependency.
Most temporal logic in business application can be single threaded, as long as the I/O can run concurrently, this is where co-routine comes in handy. However concurrent programming with co-routine, need to deal with “async” and “await”, it is still more complex than sequential programming. Can we write the program sequentially, and then speculative execution will try run it concurrently?
This is what Facebook Haxl project has demonstrated to us. The idea is simple, given we have these two tables:
CREATE TABLE `User` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`inviterId` int(11) NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
CREATE TABLE `Post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`authorId` int(11) NOT NULL,
`editorId` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
Post has author, and author has inviter. We can map the relation as computed property in code:
@sources.Mysql()
export class User extends Entity {
public id: number;
public name: string;
public inviterId: number;
public get inviter(): User {
return this.scene.load(User, { id: this.inviterId });
}
public get posts() {
return this.scene.query(Post, { authorId: this.id });
}
}
@sources.Mysql()
export class Post extends Entity {
public id: number;
public title: string;
public authorId: number;
public get author(): User {
return this.scene.load(User, { id: this.authorId });
}
public get editor(): User {
return this.scene.load(User, { id: this.editorId });
}
public get authorName(): string {
return this.author.name;
}
public get inviterName(): string {
const inviter = this.author.inviter;
return inviter ? inviter.name : 'N/A';
}
}
If we express the UI rendering logic sequentially:
const author = somePost.author
const editor = somePost.editor
return new UI({ author, editor })
Even the code is sequential, loading author and editor can be executed concurrently, as they are independent from each other. However
const author = somePost.author
const authorInviter = author.inviter
return new UI({ author, authorInviter })
Because inviter depends on author, this two lines can not be executed concurrently. We have implemented this kind of “optimization” in TypeScript, with modification of the compiler and a runtime scheduler.
Isolated
The second property to make temporal logic simple is “isolated”. Here is a frequent case where isolation is broken:
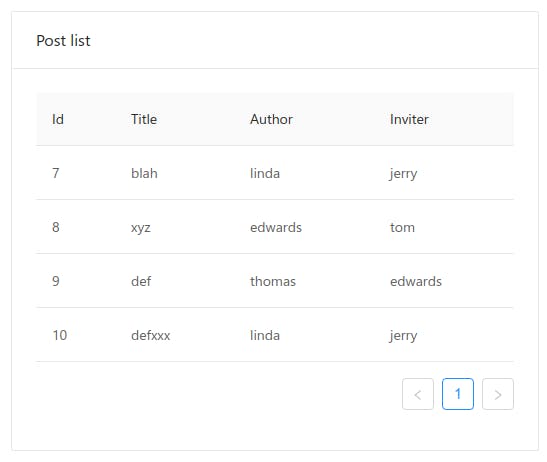
If we render this table from the “Post” object defined above, it will lead to so call “1+N” problem. For each row, there will need extra SQL to fetch author name and inviter of the author. This is where we normally ignore isolation, and load them in batch. What we want is automatically batching up the load operations.
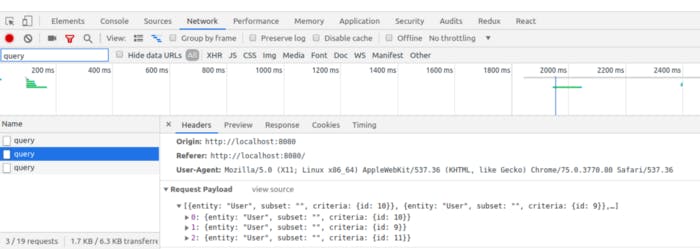
First, all the query in browser need to be batched in one big http query, with all the additional data to be fetched.
2019-07-19T11:25:04.136927Z 27 Query START TRANSACTION
2019-07-19T11:25:04.137426Z 27 Query SELECT id, title, authorId FROM Post
2019-07-19T11:25:04.138444Z 27 Query COMMIT
2019-07-19T11:25:04.772221Z 27 Query START TRANSACTION
2019-07-19T11:25:04.773019Z 27 Query SELECT id, name, inviterId FROM User WHERE id IN (10, 9, 11)
2019-07-19T11:25:04.774173Z 27 Query COMMIT
2019-07-19T11:25:04.928393Z 27 Query START TRANSACTION
2019-07-19T11:25:04.936851Z 27 Query SELECT id, name, inviterId FROM User WHERE id IN (8, 7, 9)
2019-07-19T11:25:04.937918Z 27 Query COMMIT
Then in the backend, the SQL queries should be rewritten as IN query. It is implemented by controlled coroutine call stack evaluation. Instead of doing depth-first evaluation, we do breadth-first. So all I/O operation can be collected then to be rewritten as a batch query.
This way, I/O batching as a cross cutting non-functional concern, no longer complect the essential temporal logic we want to express.
Continuous
The non-continuous version interleaves the temporal logic like this:
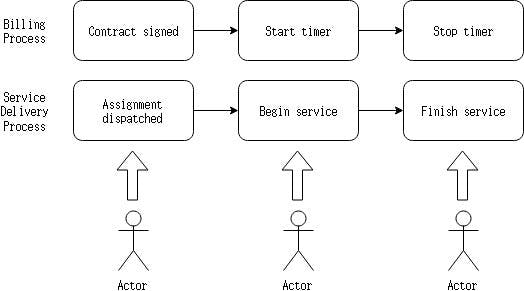
Although, billing process is more causally related, it can not be written close to each other. Although, contract singed and assignment dispatched has fewer common business, but because they are temporally related, they have to be written one after another in the order of time.
It is essentially several timelines squashed into one mainline. The POV constantly changes, in this single threaded story telling. The sequential nature is no longer a blessing, but a curse. We need to separate those independent timelines, and describes them in its own encapsulation block. It is called "Process", as business process.
Let's look at this final example
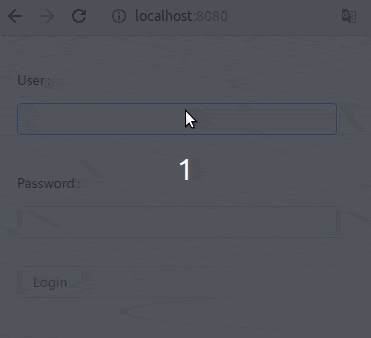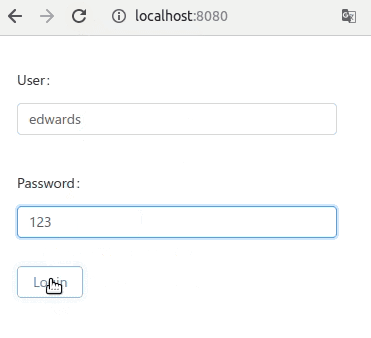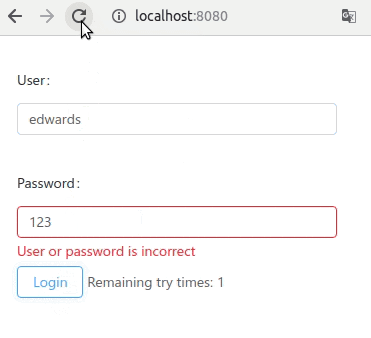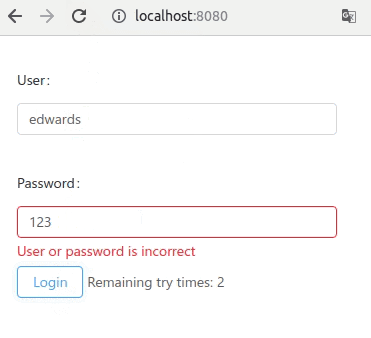
The account life-cycle can be described as a simple state machine. But in normal imperative programming style, it can be written as a continuous temporal logic. Here we have contributed a alternative style:
const MAX_RETRY_COUNT = 3;
@sources.Mysql()
export class Account extends Process {
public name: string;
// plain text, just a demo
public password: string;
public retryCount: number;
public reset: ProcessEndpoint<string, boolean>;
public login: ProcessEndpoint<string, boolean>;
public process() {
let password: string;
while (true) {
locked: this.commit();
const resetCall = this.recv('reset');
password = resetCall.request;
if (this.isPasswordComplex(password)) {
this.respond(resetCall, true);
break;
}
this.respond(resetCall, false);
}
let retryCount = MAX_RETRY_COUNT;
for (; retryCount > 0; retryCount -= 1) {
normal: this.commit();
const loginAttempt = this.recv('login');
const success = loginAttempt.request === password;
this.respond(loginAttempt, success);
if (success) {
retryCount = MAX_RETRY_COUNT + 1;
continue;
}
}
__GOBACK__('locked');
}
private isPasswordComplex(password: string) {
return password && password.length > 6;
}
}
The process() is a function with infinite loop. It is never meant to be executed forever. Every time, this.recv(), the execution breaks, and the control yield to other process.
locked: this.commit()
normal: this.commit()
statement will label is a savepoint, just like in the game. The process can be loaded back from that savepoint, and resume. But where is the process saved to? Just ordinary Mysql table:
CREATE TABLE `Account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL UNIQUE,
`password` varchar(255) NOT NULL,
`status` varchar(255) NOT NULL,
`retryCount` int(11) NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
The label will be saved in the "status" column. Other local variable, will not be saved in database, unless there is a object property with the same name (password, retryCount).
Business transaction, or moment interval in color uml, is a good fit for this kind of programming style. It also settled the problem of where to put inter-object interaction in DDD, we can put it in Process. Because the code written out this way is not very different from the box/arrow in whiteboard, and it is not very different from original business requirement, it will facilitate the communication between different groups with shared language.
Unlike BPM or workflow solutions. Process is part of the application, it can be rendered as UI, and sum/avg by the report. We do not need to maintain a extra copy of data (extra states) to feed the "engine".
The UI binding of this application looks like this:
AccountDemo.xml
<Form width="320px" margin="24px">
<Input label="User" :value="&name" />
<Input label="Password" :value="&password" />
<switch :value="status">
<slot #default><Button @onClick="onLoginClick">Login</Button></slot>
<slot #locked><Button @onClick="onResetClick">Reset</Button></slot>
</switch>
{{ notice }}
</Form>
AccountDemo.ts
@sources.Scene
export class AccountDemo extends RootSectionModel {
@constraint.required
public name: string;
@constraint.required
public password: string;
private justFailed: boolean;
private get account() {
return this.scene.tryLoad(Account, { name: this.name });
}
public get notice() {
if (this.justFailed === undefined) {
return '';
}
if (this.justFailed === false) {
return 'Login Successfully';
}
if (!this.account) {
return '';
}
if (this.account.status === 'locked') {
return 'Account has been locked';
}
return `Remaining try times: ${this.account.retryCount}`;
}
public get status() {
if (!this.justFailed || !this.account) {
return 'default';
}
return this.account.status;
}
public onLoginClick() {
if (constraint.validate(this)) {
return;
}
if (!this.account) {
constraint.reportViolation(this, 'password', {
message: 'User or password is incorrect',
});
return;
}
try {
const success = this.account.login(this.password);
if (!success) {
throw new Error('failed');
}
this.justFailed = false;
} catch (e) {
this.justFailed = true;
constraint.reportViolation(this, 'password', {
message: 'User or password is incorrect',
});
return;
}
}
public onResetClick() {
if (this.account) {
this.account.reset('p@55word');
}
}
}
Conclusion
We are building a aPaaS product called MulCloud to enable this kind of programming style. It has identical syntax with TypeScript, and inherited a lot of familiar ideas. We believe our approach, not only simplified programming, and because we stand-upon giant shoulders, people will also find it to be easy.
There is one more caution to leave behind for future innovators:
MulCloud has to put a lot of effort to build observability solution to allow the developer debug in production. Old-school imperative programming despite the odds, it has one shiny virtue: it has one-to-one mapping with the instruction stream executed by the CPU. By building the program in sequential / isolated / continuous way, the source code is detached from the reality, which is concurrent / entangled / with lots of long range causality. When something goes wrong in the wild, it is harder, much harder to debug. Bret Victor has demonstrated a lot of cool ideas on providing more runtime feedback. We borrowed a lot of them, but that deserves another post.
Simplicity is hard, when simplicity is not the reality.