



Introduction
Content creation revolves around authenticity in delivering required knowledge that not only informs a learner and the versed audience but also helps them grow in skill which results in the application of the knowledge acquired. From YouTube feedback of the content created based on the views and comments one can be able to determine the quality of the video based on the sentiments of views. Let us get to it.
Prerequisite
- Python and the relevant libraries
- Jupyter Notebook, VScode and PyCharm editors depending on your preference.
- Google Cloud Platform
Setting Environment
We will need the textblob, wordcloud libraries for the sentimental analysis. The pandas, numpy and re libraries will help in cleaning, restructuring and summarizing statistics of the data. We will use the matplotlib library for visualization of our data.
# Import libraries
from textblob import TextBlob
from wordcloud import WordCloud
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
Data
In an attempt to analyze the sentiments of the SQL content in YouTube, we picked three videos with a high number of comments from Edureka, freeCodeCamp and Programming with Mosh YouTube Channels. The three have been extracted from the YouTube data extracted by the SerpApi Tool.
From the Google Cloud Platform acquire a YouTube API key which will be inserted in the below comment extraction tool:
# Scrape Comments for SQL Using Python Through The Youtube Data API
api_key = "your Api key here" # Insert your Api key here.
from googleapiclient.discovery import build
youtube = build('youtube', 'v3', developerKey=api_key)
import pandas as pd
box = [['Name', 'Comment', 'Time', 'Likes', 'Reply Count']]
#Eudereka, Programming with Mosh, freeCodeCamp
code_lang = [
{"id":"HXV3zeQKqGY"},
{"id":"7S_tz1z_5bA"},
{"id":"zbMHLJ0dY4w"}
]
# sql_vids = pd.DataFrame([])
for id_code in code_lang:
def scrape_comments_with_replies():
data = youtube.commentThreads().list(part='snippet', videoId=id_code['id'], maxResults='100', textFormat="plainText").execute()
for i in data["items"]:
name = i["snippet"]['topLevelComment']["snippet"]["authorDisplayName"]
comment = i["snippet"]['topLevelComment']["snippet"]["textDisplay"]
published_at = i["snippet"]['topLevelComment']["snippet"]['publishedAt']
likes = i["snippet"]['topLevelComment']["snippet"]['likeCount']
replies = i["snippet"]['totalReplyCount']
box.append([name, comment, published_at, likes, replies])
totalReplyCount = i["snippet"]['totalReplyCount']
if totalReplyCount > 0:
parent = i["snippet"]['topLevelComment']["id"]
data2 = youtube.comments().list(part='snippet', maxResults='100', parentId=parent,
textFormat="plainText").execute()
for i in data2["items"]:
name = i["snippet"]["authorDisplayName"]
comment = i["snippet"]["textDisplay"]
published_at = i["snippet"]['publishedAt']
likes = i["snippet"]['likeCount']
replies = ""
box.append([name, comment, published_at, likes, replies])
while ("nextPageToken" in data):
data = youtube.commentThreads().list(part='snippet', videoId=id_code['id'], pageToken=data["nextPageToken"],
maxResults='100', textFormat="plainText").execute()
for i in data["items"]:
name = i["snippet"]['topLevelComment']["snippet"]["authorDisplayName"]
comment = i["snippet"]['topLevelComment']["snippet"]["textDisplay"]
published_at = i["snippet"]['topLevelComment']["snippet"]['publishedAt']
likes = i["snippet"]['topLevelComment']["snippet"]['likeCount']
replies = i["snippet"]['totalReplyCount']
box.append([name, comment, published_at, likes, replies])
totalReplyCount = i["snippet"]['totalReplyCount']
if totalReplyCount > 0:
parent = i["snippet"]['topLevelComment']["id"]
data2 = youtube.comments().list(part='snippet', maxResults='100', parentId=parent,
textFormat="plainText").execute()
for i in data2["items"]:
name = i["snippet"]["authorDisplayName"]
comment = i["snippet"]["textDisplay"]
published_at = i["snippet"]['publishedAt']
likes = i["snippet"]['likeCount']
replies = ''
box.append([name, comment, published_at, likes, replies])
df = pd.DataFrame({'Name': [i[0] for i in box], 'Comment': [i[1] for i in box], 'Time': [i[2] for i in box],
'Likes': [i[3] for i in box], 'Reply Count': [i[4] for i in box]})
sql_vids = pd.DataFrame([])
sql_vids = sql_vids.append(df, ignore_index = True)
sql_vids.to_csv('youtube-comments.csv', index=False, header=False)
scrape_comments_with_replies()
The data is then stored in the CSV file from whence our analysis begins.
Import the data
Depending on the location of your data file import it using the pandas function:
# import data:
data = pd.read_csv(r'youtube-comments.csv',
lineterminator='\n')
data.head()
The data head gives you the first five rows of the data:
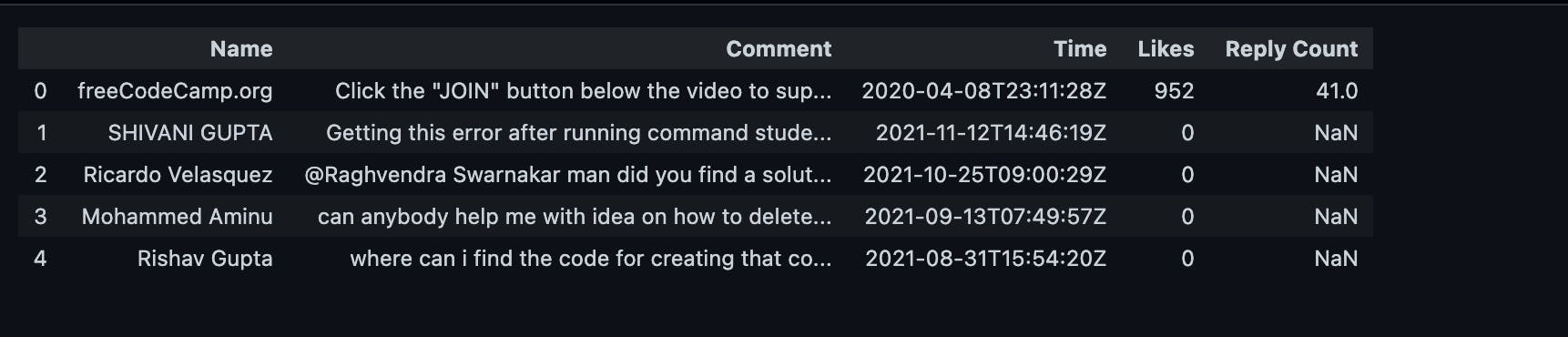
Clean the Comments
To carry out the sentimental analysis, we will now remove the punctuation marks in the Comment strings by the function:
# Clean the text:
# Function
def cleanTxt(text):
text = re.sub(r'[^\w]', ' ', text)
return text
data['Comment'] = data['Comment'].apply(cleanTxt)
Sentimental Analysis
Polarity and Subjectivity
In starting with the analysis we will create the new columns namely Polarity and Subjectivity and acquire the very values of each comment. Polarity ranges from -1 to 1 and measures how positive or negative a comment is. It simply means emotions expressed in a sentence. Subjectivity expresses some personal feelings, views, or beliefs. A subjective sentence may not express any sentiment.
To find the two, use the defined function using the textblob library:
# get subjectivity
def getSubjectivity(text):
return TextBlob(text).sentiment.subjectivity
# get polarity
def getPolarity(text):
return TextBlob(text).sentiment.polarity
#Columns
data['Subjectivity'] = data['Comment'].apply(getSubjectivity)
data['Polarity'] = data['Comment'].apply(getPolarity)
data
The two will be added to the data as follows:

WordCloud
In an attempt to view the most used words in the comment we will use the Word Cloud library to view. It is from these words that we get the Polarity of a comment. To view this:
# WordCloud
allWords = ' '.join( [cmts for cmts in data['Comment']])
wordCloud = WordCloud(width = 500, height = 300, random_state = 21, max_font_size = 119).generate(allWords)
plt.imshow(wordCloud, interpolation= 'bilinear')
plt.axis('off')
plt.show

As noted from the above word cloud the most used words are Thank, video, SQL, course, link, zip file, tutorial, database, download. Most of these words are relatable to the content and suggest the in-depth skills that the learners desire to grow using the SQL tool. Thank being the dominant word suggests gratitude and high positive response.
Is this true?
The answer can be found by the code below:
- First, compute the Analysis:
# function to compute analysis
def getAnalysis(score):
if score < 0 :
return 'Negative'
elif score == 0:
return 'Neutral'
else:
return 'Positive'
data['Analysis'] = data['Polarity'].apply(getAnalysis)
- Compute the percentages of the analysis:
# % Percentages:
pcomments = data[data.Analysis == 'Positive']
pcomments = pcomments['Comment']
print('Positive: ' +str(round((pcomments.shape[0]/data.shape[0])*100, 1))+ '%')
ncomments = data[data.Analysis == 'Negative']
ncomments = ncomments['Comment']
print('Negative: ' +str(round((ncomments.shape[0]/data.shape[0])*100, 1))+ '%')
nucomments = data[data.Analysis == 'Neutral']
nucomments = nucomments['Comment']
print('Nuetral: ' +str(round((nucomments.shape[0]/data.shape[0])*100, 1))+ '%')
Output
Positive: 46.0%
Negative: 9.3%
Nuetral: 44.7%
From the comments, most learners perceive the use of the SQL content from Eudereka, freeCodecamp and Programming with Mosh as very useful. 46.0% agree that the content is useful and 9.3% do not agree. From this anyone desiring to learn SQL is advised to subscribe to the content of these three bloggers. The statistics suggest that the bloggers give in-depth knowledge of the SQL tool that is beneficial to a beginner in this field.
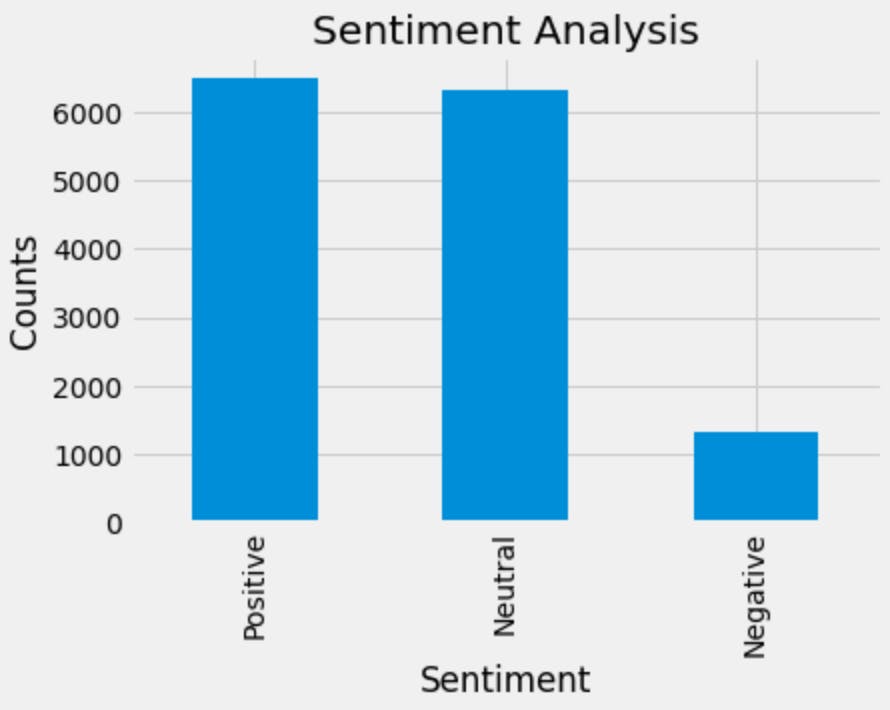
To graph the above do:
# Value Count
data['Analysis'].value_counts
# Plot
plt.title('Sentiment Analysis')
plt.xlabel('Sentiment')
plt.ylabel('Counts')
data['Analysis'].value_counts().plot(kind= 'bar')
plt.show()
Conclusion
From the three platforms; Edureka, freeCodeCamp and Programming with Mosh the SQL, as a data tool, content is very useful. These are not the only bloggers with such content hence from a learner desiring to perform a preferential analysis, one can find the above tool in this GitHub repo.
You can also contribute to our user forum here: forum.serpapi.com
If you'd like to contribute either by sharing suggestions, recommendations and any questions, feel free to drop a comment in the comment section or reach out to me via Twitter at @mabwa, or @serp_api.