



This article was originally posted on the Neptune blog.
The International Conference on Learning Representations (ICLR) took place last week, and I had a pleasure to participate in it. ICLR is an event dedicated to research on all aspects of representation learning, commonly known as deep learning. This year the event was a bit different as it went virtual due to the coronavirus pandemic. However, the online format didn't change the great atmosphere of the event. It was engaging and interactive and attracted 5600 attendees (twice as many as last year). If you're interested in what organizers think about the unusual online arrangement of the conference, you can read about it here.
Over 1300 speakers presented many interesting papers, so I decided to create a series of blog posts summarizing the best of them in four main areas: deep learning, reinforcement learning, generative modeling, NLP/NLU.
This is the last post of the series, in which I want to share 10 best Natural Language Processing/Understanding contributions from the ICLR.
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- A Mutual Information Maximization Perspective of Language Representation Learning
- Mogrifier LSTM
- High Fidelity Speech Synthesis with Adversarial Networks
- Reformer: The Efficient Transformer
- DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling
- Depth-Adaptive Transformer
- On Identifiability in Transformers
- Mirror-Generative Neural Machine Translation
- FreeLB: Enhanced Adversarial Training for Natural Language Understanding
Best Natural Language Processing/Understanding Papers
1. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
A new pretraining method that establishes new state-of-the-art results on the GLUE, RACE, and SQuAD benchmarks while having fewer parameters compared to BERT-large. (TL;DR, from OpenReview.net)
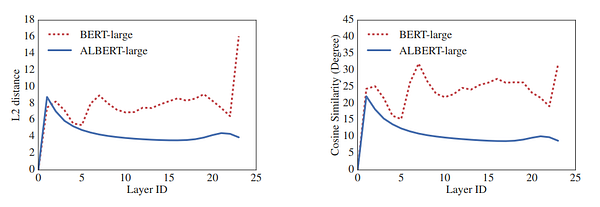

2. A Mutual Information Maximization Perspective of Language Representation Learning
Word representation is a common task in NLP. Here, authors formulate new frameworks that combine classical word embedding techniques (like Skip-gram) with more modern approaches based on contextual embedding (BERT, XLNet).
| Paper |
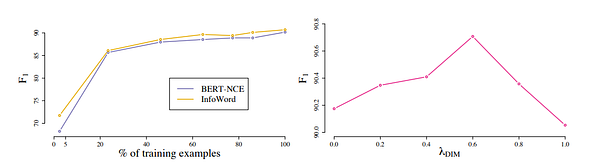

3. Mogrifier LSTM
An LSTM extension with state-of-the-art language modelling results. (TL;DR, from OpenReview.net)
| Paper |

4. High Fidelity Speech Synthesis with Adversarial Networks
We introduce GAN-TTS, a Generative Adversarial Network for Text-to-Speech, which achieves Mean Opinion Score (MOS) 4.2. (TL;DR, from OpenReview.net)

First author: Mikołaj Bińkowski | LinkedIn | GitHub |
5. Reformer: The Efficient Transformer
Efficient Transformer with locality-sensitive hashing and reversible layers. (TL;DR, from OpenReview.net)
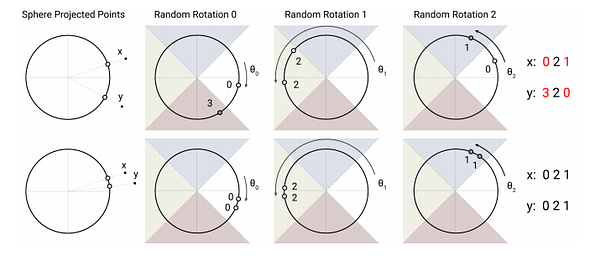
Main authors:


6. DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling
DeFINE uses a deep, hierarchical, sparse network with new skip connections to learn better word embeddings efficiently. (TL;DR, from OpenReview.net)
| Paper |
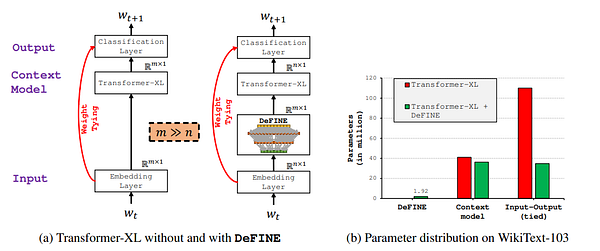

First author: | Twitter | LinkedIn | GitHub | Website |
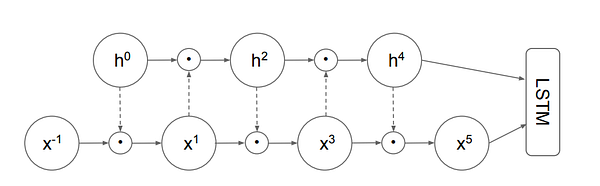
7. Depth-Adaptive Transformer
Sequence model that dynamically adjusts the amount of computation for each input. (TL;DR, from OpenReview.net)
| Paper |
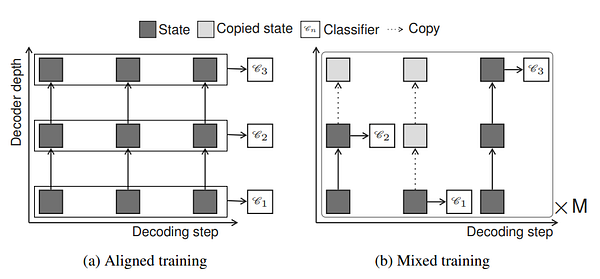
Training regimes for decoder networks able to emit outputs at any layer. Aligned training optimizes all output classifiers Cn simultaneously assuming all previous hidden states for the current layer are available. Mixed training samples M paths of random exits at which the model is assumed to have exited; missing previous hidden states are copied from below. (source: Fig 1, from the paper)

First author: Maha Elbayad Twitter | LinkedIn | GitHub | Website |
8. On Identifiability in Transformers
We investigate the identifiability and interpretability of attention distributions and tokens within contextual embeddings in the self-attention based BERT model. (TL;DR, from OpenReview.net)
| Paper |
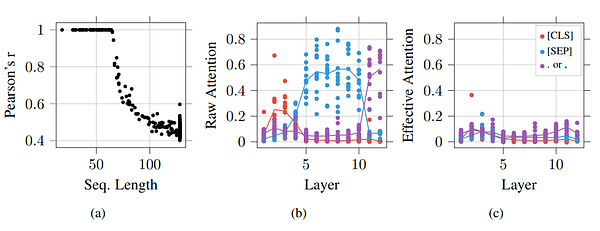

First author: Gino Brunner | Twitter | LinkedIn | Website |
9. Mirror-Generative Neural Machine Translation
Translation approaches known as Neural Machine Translation models (NMT), depend on availability of large corpus, constructed as a language pair. Here, a new method is proposed for translations in both directions using generative neural machine translation.
| Paper |

First author: Zaixiang Zheng | Twitter | Website |
10. FreeLB: Enhanced Adversarial Training for Natural Language Understanding
Here, the authors propose a new algorithm, called FreeLB that formulate a novel approach to the adversarial training of the language model is proposed.

 First author: Chen Zhu
| LinkedIn | GitHub | Website |
First author: Chen Zhu
| LinkedIn | GitHub | Website |
Summary
Depth and breadth of the ICLR publications is quite inspiring. This post focuses on the "Natural Language Processing" topic, which is one of the main areas discussed during the conference. According to this analysis, these areas include:
- Deep learning (here)
- Reinforcement learning (here)
- Generative models (here)
- Natural Language Processing/Understanding (covered in this post)
In order to create a more complete overview of the top papers at ICLR, we have built a series of posts, each focused on one topic mentioned above. This is the last one, so you may want to check the others for a more complete overview. We would be happy to extend our list, so feel free to share other interesting NLP/NLU papers with us. In the meantime - happy reading!
This article was originally on the Neptune blog where you can find more in-depth articles for machine learning practitioners.