


BigQuery is great at handling large datasets, but will never give you a sub-second response, even on small datasets. It leads to a wait time on dashboards and charts, especially dynamic, where users can select different date ranges or change filters. It is almost always okay for internal BIs, but not for customer-facing analytics. We tolerate a lot of things such as poor UI and performance in internal tools, but not in those we ship to customers.
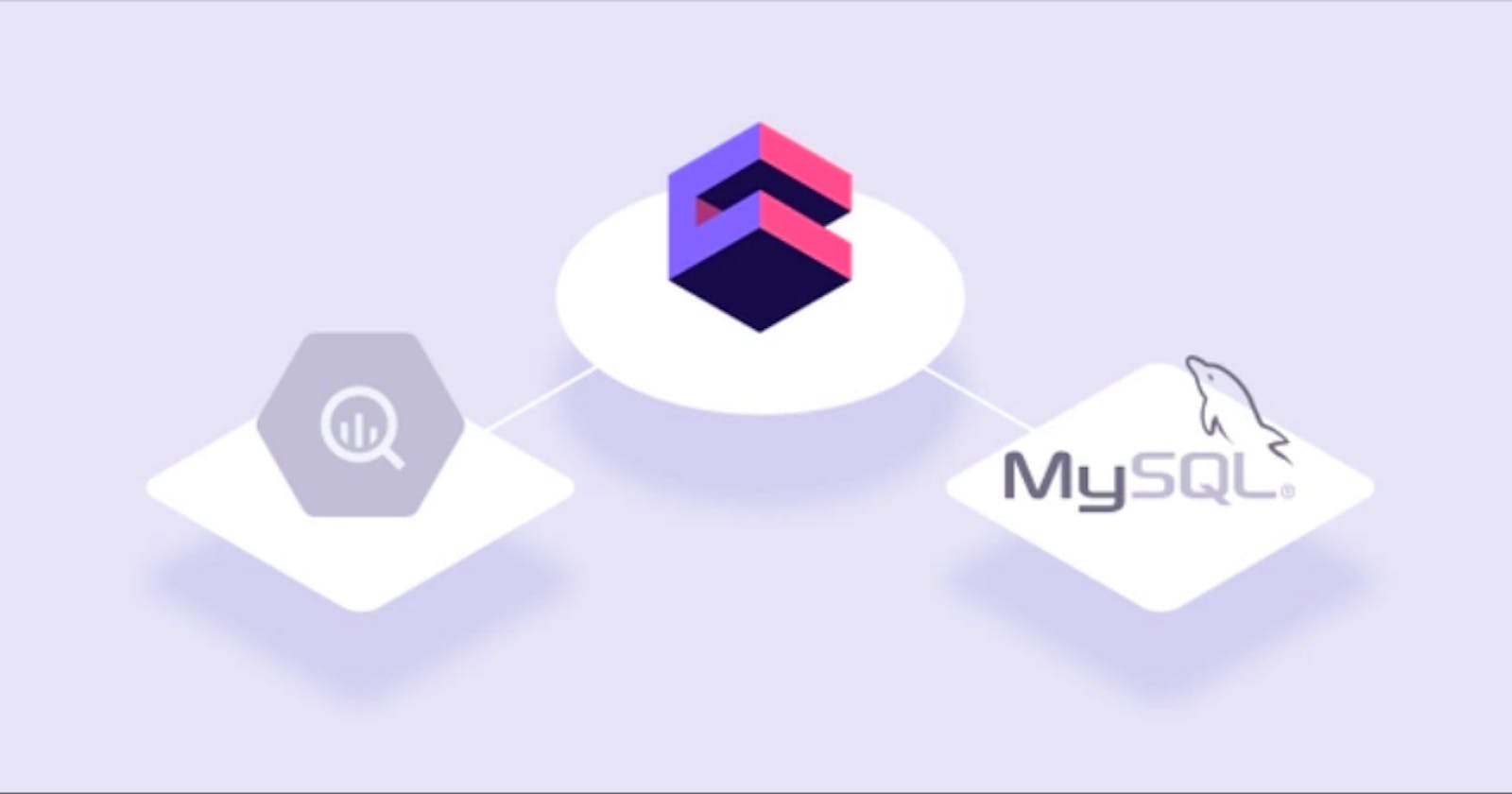
But we still can leverage BigQuery’s cheap data storage and the power to process large datasets, while not giving up on the performance. As BigQuery acts as a single source of truth and stores all the raw data, MySQL can act as cache layer on top of it and store only small, aggregated tables and provides us with a desired sub-second response.
You can check out the demo here and the source code on Github . Make sure to play with date range and switchers—dynamic dashboards benefit the most from the pre-aggregations.
Cube.js leverages the pre-aggregations layer as a part of its two-level caching system . We recently released support for external pre-aggregations to target use cases, where users can combine multiple databases and get the best out of the two worlds. The schema below shows the typical setup for Cube.js with BigQuery and MySQL.

To use the external rollup feature, we need to configure Cube.js to connect to both BigQuery and MySQL, as well as specify which pre-aggregation we want to build externally. If you are new to Cube.js, I recommend checking this 101-style tutorial first and then come back here. We are going to use the public Hacker News dataset from BigQuery for our sample application.
Let’s first install Cube.js CLI and create a new application.
$ npm install -g cubejs-cli
$ cubejs create external-rollups -d bigquery
We set -d bigquery to make our main database be a BigQuery. Next, cd into the bigquery-mysql folder and configure .env with correct credentials.
CUBEJS_DB_TYPE=bigquery
CUBEJS_DB_BQ_PROJECT_ID=<BIGQUERY PROJECT ID>
CUBEJS_DB_BQ_CREDENTIALS=<BIGQUERY BASE64-ENCODED KEY>
CUBEJS_EXT_DB_NAME=preags
CUBEJS_EXT_DB_HOST=localhost
CUBEJS_EXT_DB_USER=root
CUBEJS_EXT_DB_PASS=12345
Here we set credentials for both the main DB (BigQuery) and external DB for pre-aggregations (MySQL). You can learn more about obtaining BigQuery credentials at the Cube.js docs here . Also, in order to build pre-aggregations inside MySQL, Cube.js should have write access to the stb_pre_aggregations schema where pre-aggregation tables will be stored.
Now, let’s install the Cube.js MySQL driver.
$ npm install @cubejs-backend/mysql-driver --save
Once we have it, the last configuration step is to provide MySQL related options via the externalDbType and externalDriverFactory properties. Replace the content of the index.js file with the following.
const CubejsServer = require("@cubejs-backend/server");
const MySQLDriver = require('@cubejs-backend/mysql-driver');
const server = new CubejsServer({
externalDbType: 'mysql',
externalDriverFactory: () => new MySQLDriver({
host: process.env.CUBEJS_EXT_DB_HOST,
database: process.env.CUBEJS_EXT_DB_NAME,
user: process.env.CUBEJS_EXT_DB_USER,
password: process.env.CUBEJS_EXT_DB_PASS.toString()
})
});
server.listen().then(({ port }) => {
console.log(`🚀 Cube.js server is listening on ${port}`);
});
That is all we need to let Cube.js connect to both BigQuery and MySQL. Now, we can create our first Cube.js data schema file. Cube.js uses the data schema to generate an SQL code, which will be executed in your database.
Create the schema/Stories.js file with the following content.
cube(`Stories`, {
sql: `select * from \`fh-bigquery.hackernews.full_partitioned\` WHERE type = 'story'`,
measures: {
count: {
type: `count`,
}
},
dimensions: {
category: {
type: `string`,
case: {
when: [
{ sql: `STARTS_WITH(title, "Show HN")`, label: `Show HN` },
{ sql: `STARTS_WITH(title, "Ask HN")`, label: `Ask HN` }
],
else: { label: `Other` }
}
},
time: {
sql: `timestamp`,
type: `time`
}
}
});
Now start the Cube.js server by running node index.js and navigate to the development playground at localhost:4000.
You can select the Stories count measure and category dimension, alongside a time dimension to build a chart as shown below.
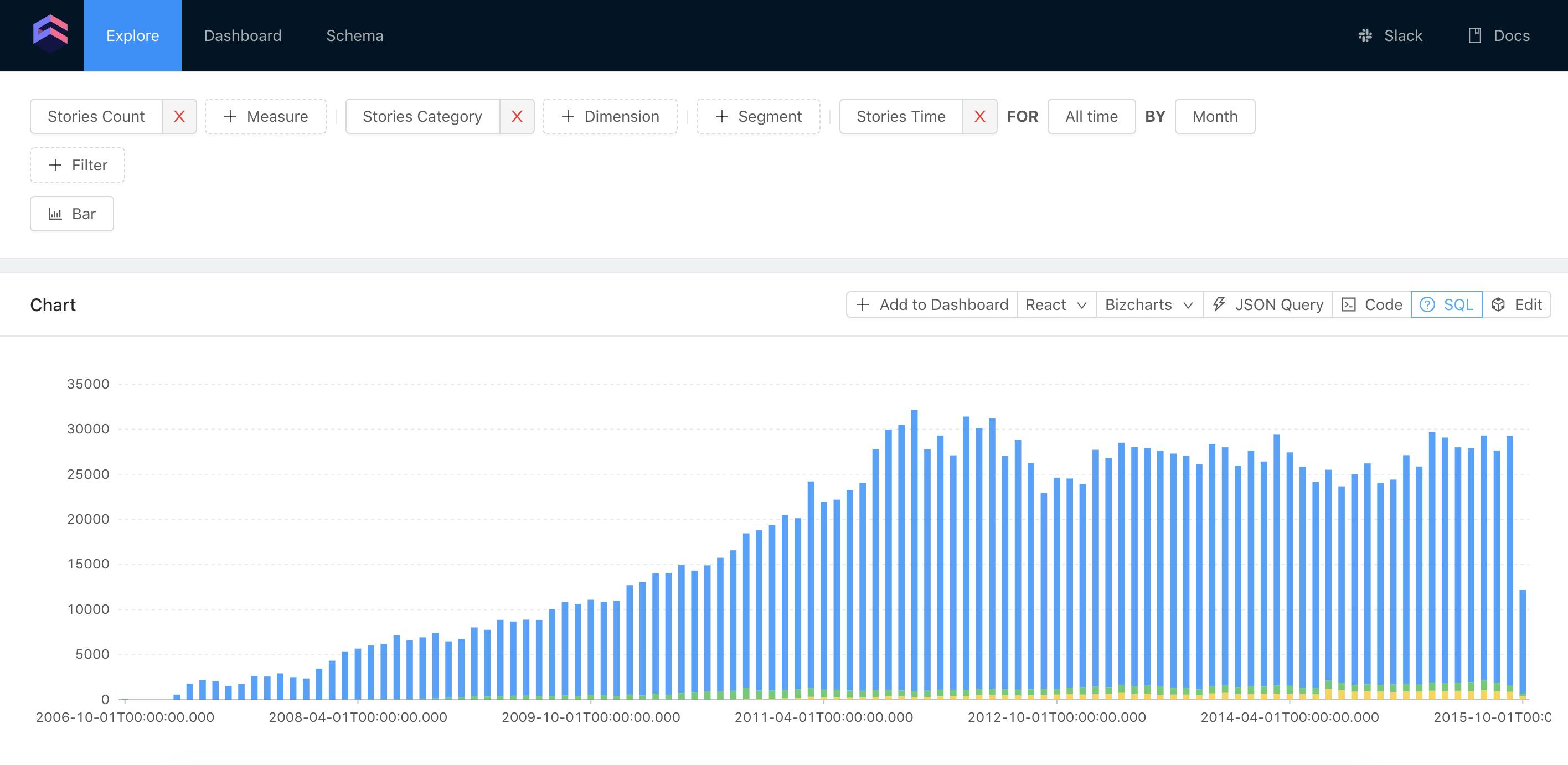
If we inspect a generated SQL by clicking a SQL button, we’ll see the following.
SELECT
CASE
WHEN STARTS_WITH(title, "Show HN") THEN 'Show HN'
WHEN STARTS_WITH(title, "Ask HN") THEN 'Ask HN'
ELSE 'Other'
END `stories__category`,
DATETIME_TRUNC(DATETIME(`stories`.timestamp, 'UTC'), MONTH) `stories__time_month`,
count(*) `stories__count`
FROM
(
select
*
from
`fh-bigquery.hackernews.full_partitioned`
WHERE
type = 'story'
) AS `stories`
GROUP BY
1,
2
ORDER BY
2 ASC
LIMIT
10000
This SQL shows us that this query runs against the raw data inside BigQuery. Now, let’s make it run against the pre-aggregated table inside MySQL. To do that, we are going to define a pre-aggregation. Usually, it is done inside the same cube, but for the sake of the tutorial, so we can compare the performance with and without pre-aggregation, let’s create a new cube. We can do it inside the same file. Add the following code to the schema/Stories.js file.
cube(`StoriesPreAgg`, {
extends: Stories,
preAggregations: {
main: {
type: `rollup`,
measureReferences: [count],
dimensionReferences: [category],
granularity: `month`,
timeDimensionReference: time,
external: true
}
}
});
In the above code, we declare a pre-aggregation with a rollup type and specify which measures and dimensions to include in the aggregate table. Also note external: true; this line tells Cube.js to upload this pre-aggregation into MySQL.
Now, go to the development playground and select the same measures and dimensions as before: count, category, and time grouped by month, but this time select them from the Stories PreAgg cube. When requested the first time, Cube.js will generate an aggregate table and upload it to MySQL. All subsequent requests will go directly to the aggregate table inside MySQL. You can inspect the generated SQL and it should look like the following.
SELECT
`stories_pre_agg__category` `stories_pre_agg__category`,
`stories_pre_agg__time_month` `stories_pre_agg__time_month`,
sum(`stories_pre_agg__count`) `stories_pre_agg__count`
FROM
stb_pre_aggregations.stories_pre_agg_main
GROUP BY
1,
2
ORDER BY
2 ASC
LIMIT
10000
As you can see, it now queries data from the stb_pre_aggregations.stories_pre_agg_main table inside MySQL. You can play around with filters to see the performance boost of the aggregated query compared to the raw one.
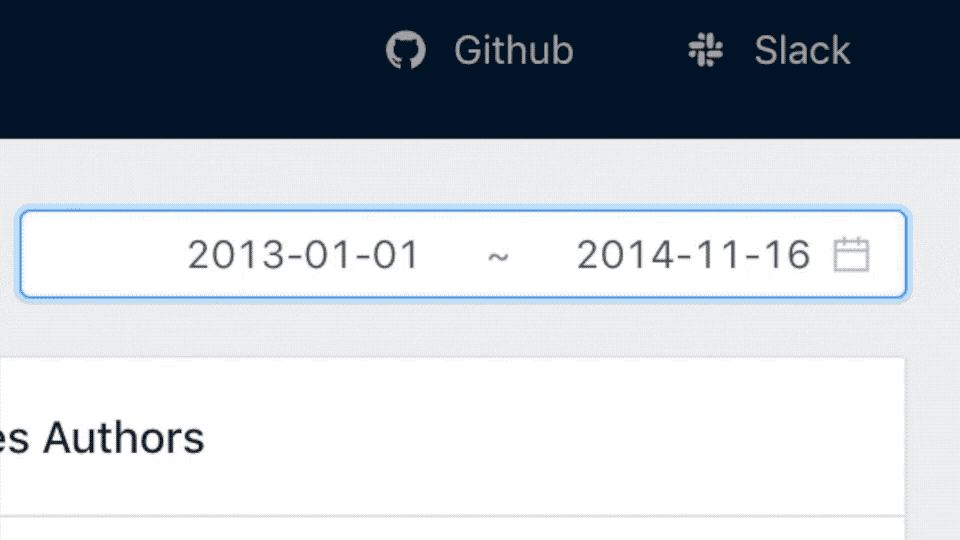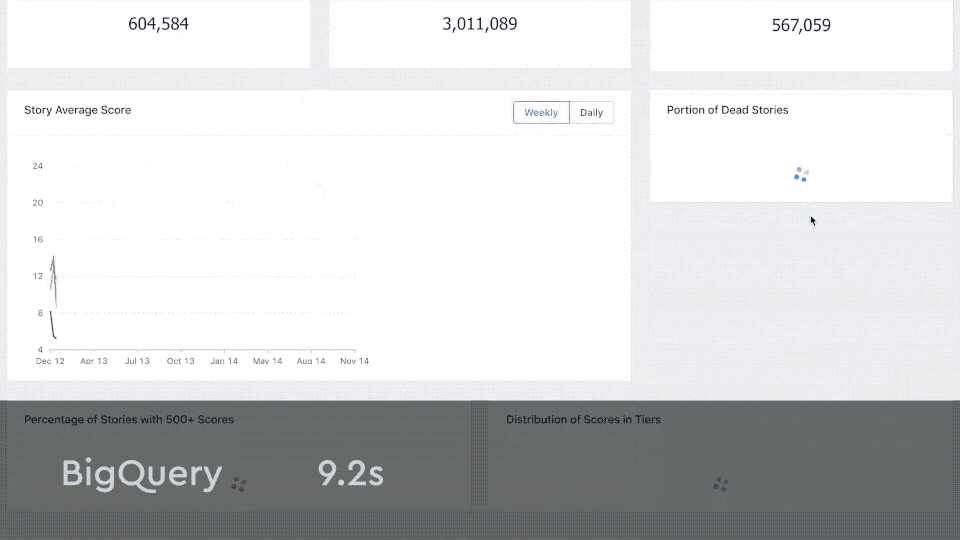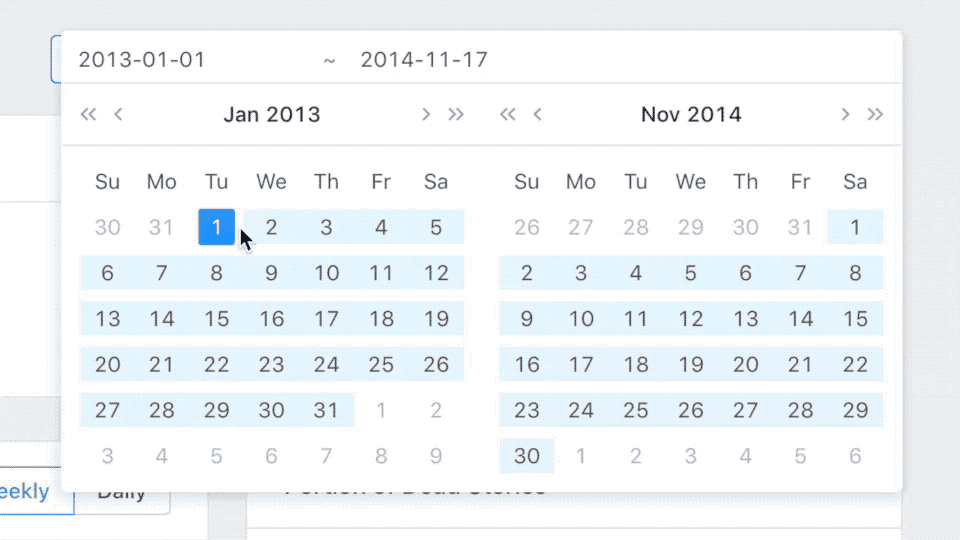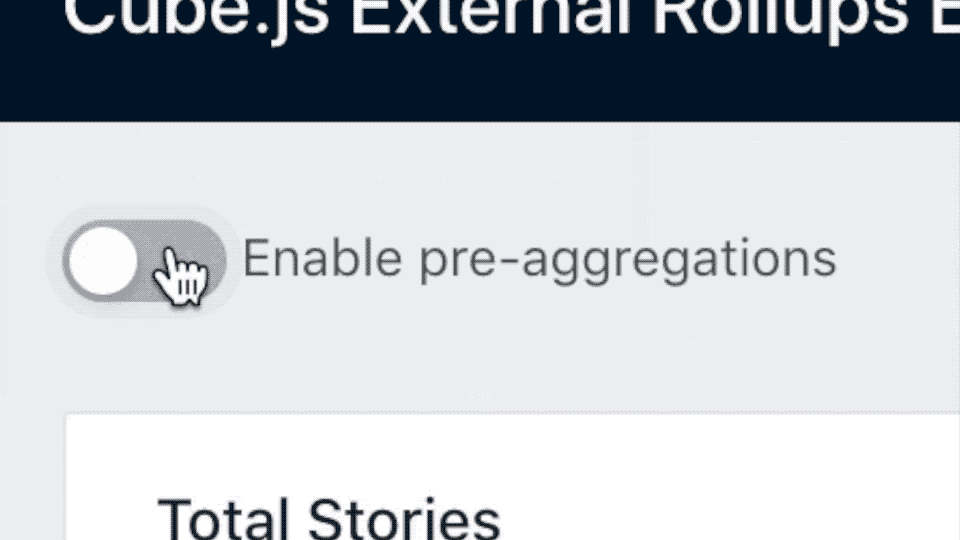
You can also check this demo dashboard with multiple charts and compare its performance with and without pre-aggregations. The source code of the example dashboard is available on Github.