@ingero

Ingero Team
@ingeroJoined April 2026
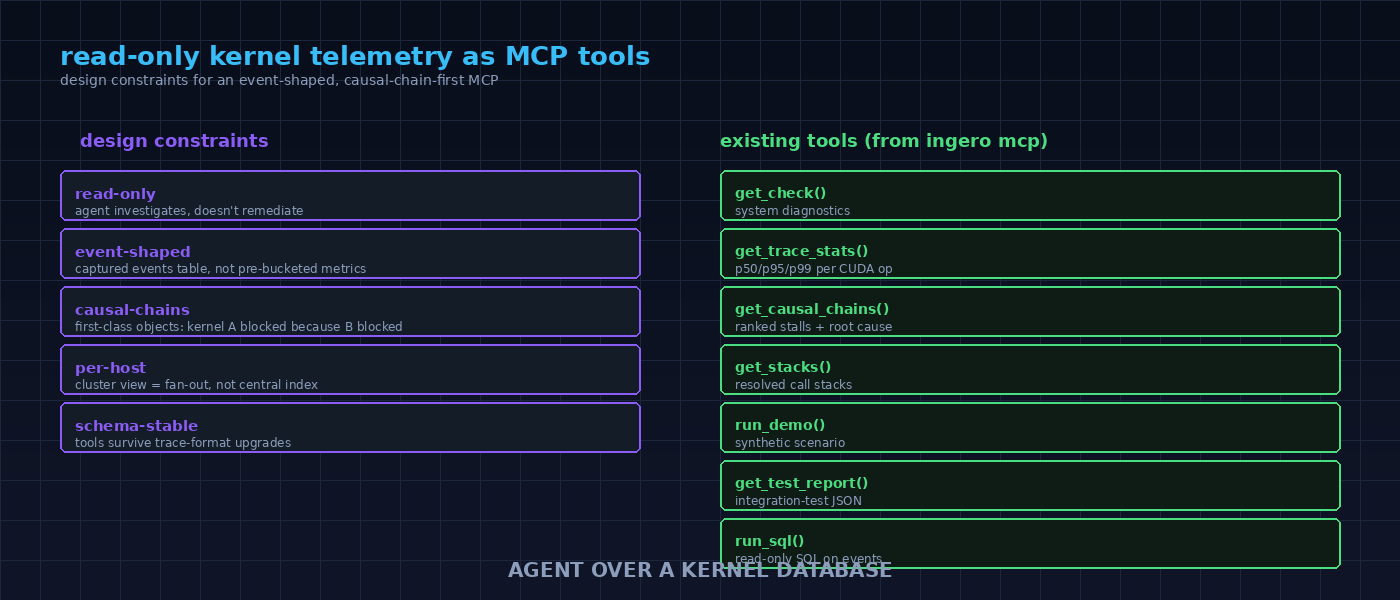
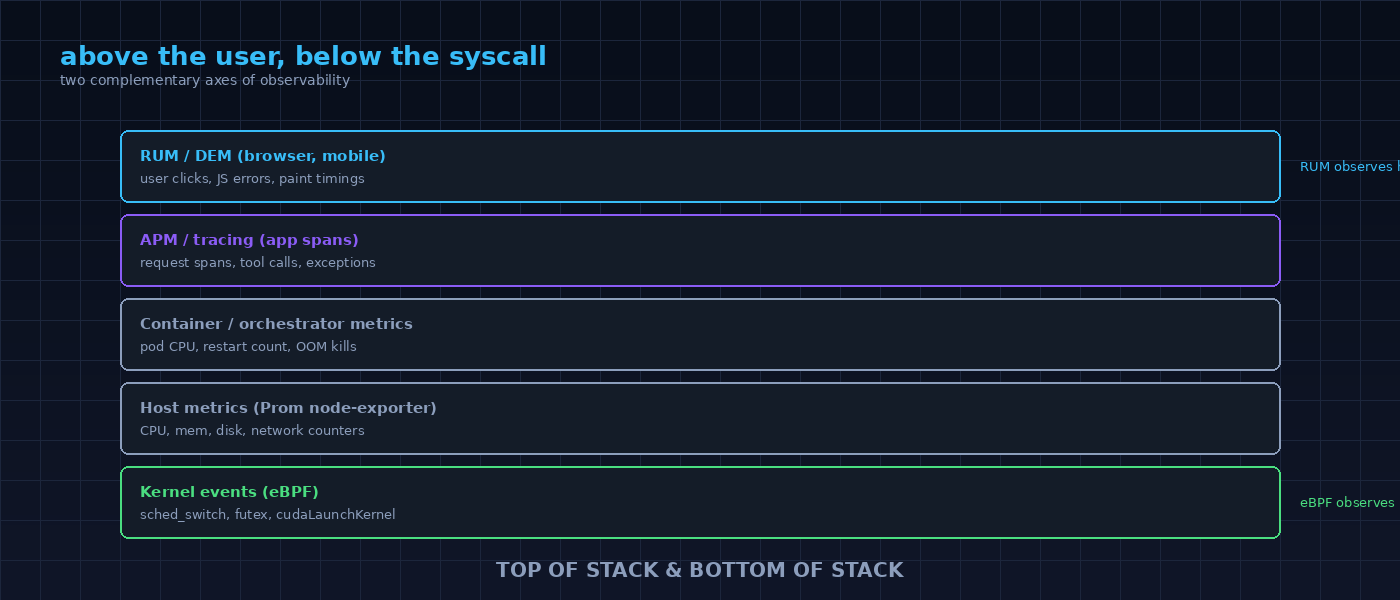
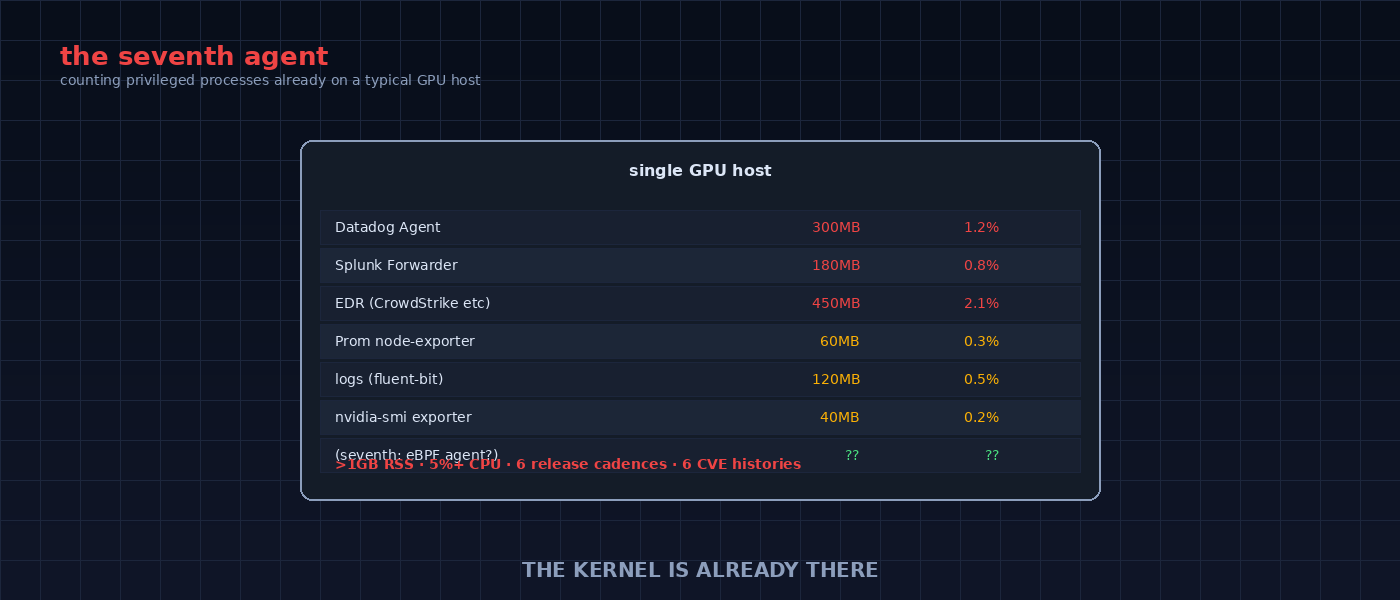
An open-source research project focused on kernel-level GPU observability and tracing CPU-GPU interactions using eBPF
About
An open-source research project focused on kernel-level GPU observability and tracing CPU-GPU interactions using eBPF
Available for
Nothing here yet.