




Ansible
Ansible is an open-source automation tool, or platform, used for IT tasks such as configuration management, application deployment, intraservice orchestration, and provisioning. It delivers simple IT automation that ends repetitive tasks and frees up DevOps teams for more strategic work.
Ansible doesn't depend on agent software and, most importantly, no additional custom security infrastructure, so this makes it easy to deploy. The following implementations describe the work of Ansible in Hadoop Automation.
Hadoop
Apache Hadoop is a collection of open-source software utilities that facilitates using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.
For creating a Hadoop cluster, we need to do some configurations manually. But to save time and effort, Ansible can be used for automating the entire process.
This Article will be the step by step guide to configure the Hadoop cluster from Ansible.
Pre-requisites:
Ansible software
Java Development Kit (JDK 8) in the Controller
Hadoop (latest version) in the Controller
We have to start three Operating Systems, VMs in our case - One being the controller and the other two being the Master and Slave nodes for the Cluster. For automating the configuration, we will have to write two playbooks for master and slave node configuration respectively. Before writing the playbook, we have to edit the Ansible inventory as well as the Hosts file where we mention the IP addresses of the other Virtual Machines.
Step-1 Create a Host file where you can store all the IP of Data Node and Name Node

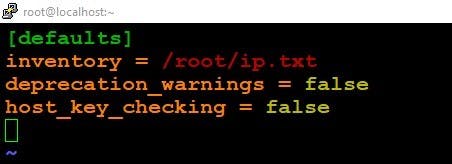
Step-2 Create an Inventory file

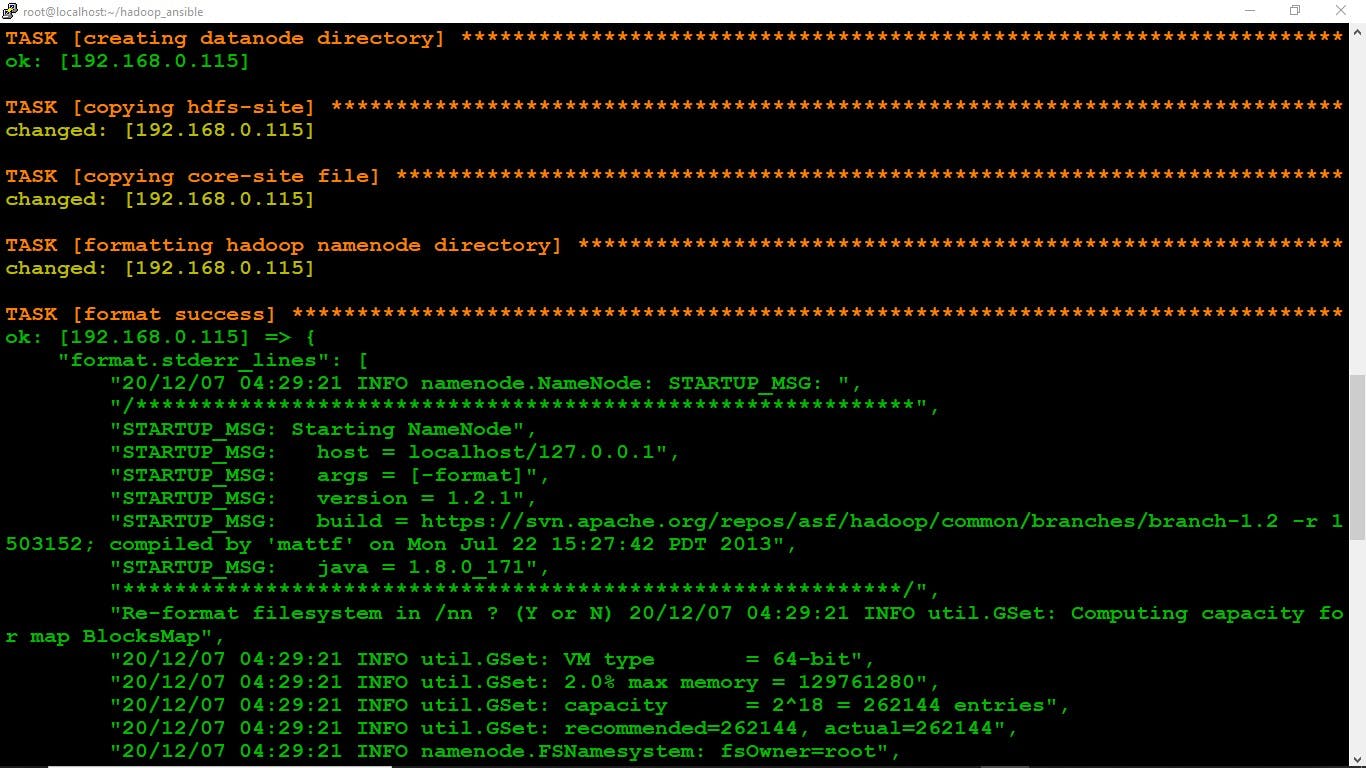
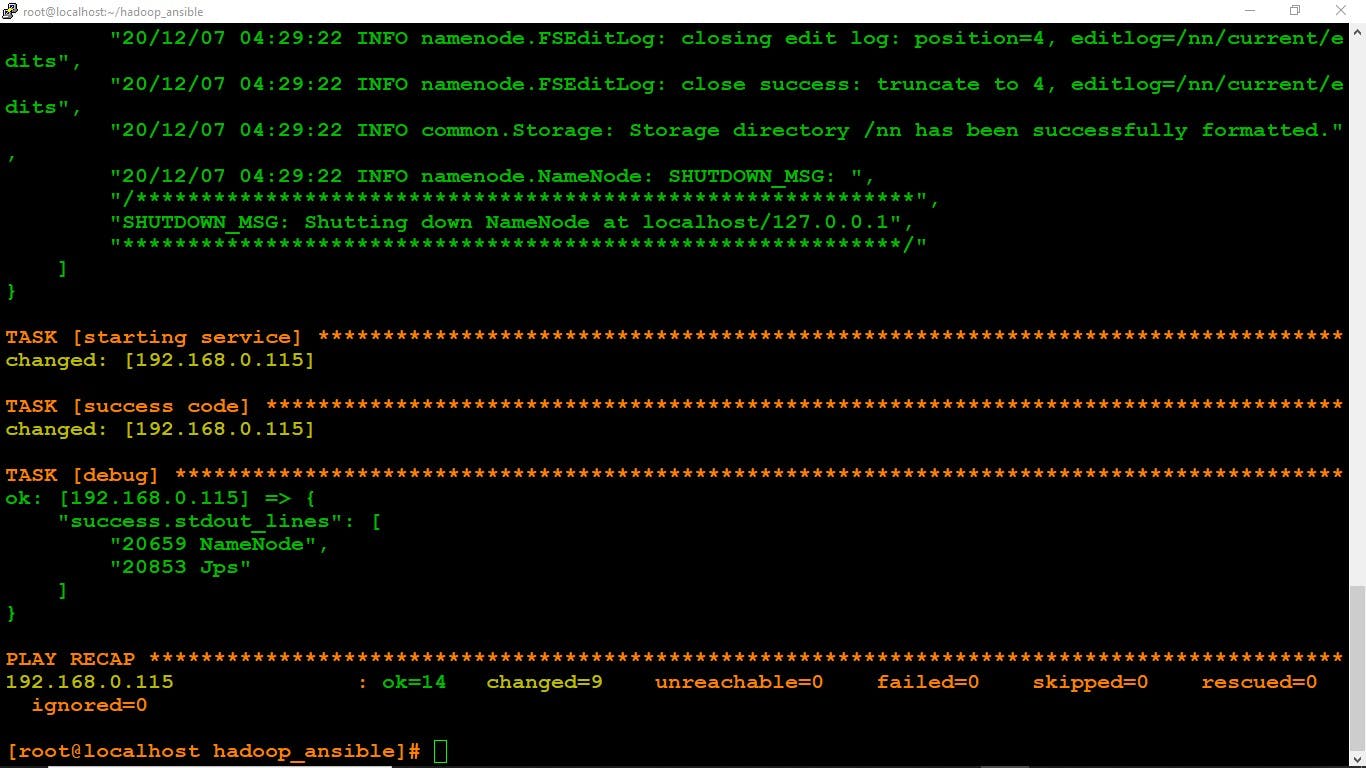
- The Namenode is successfully configured
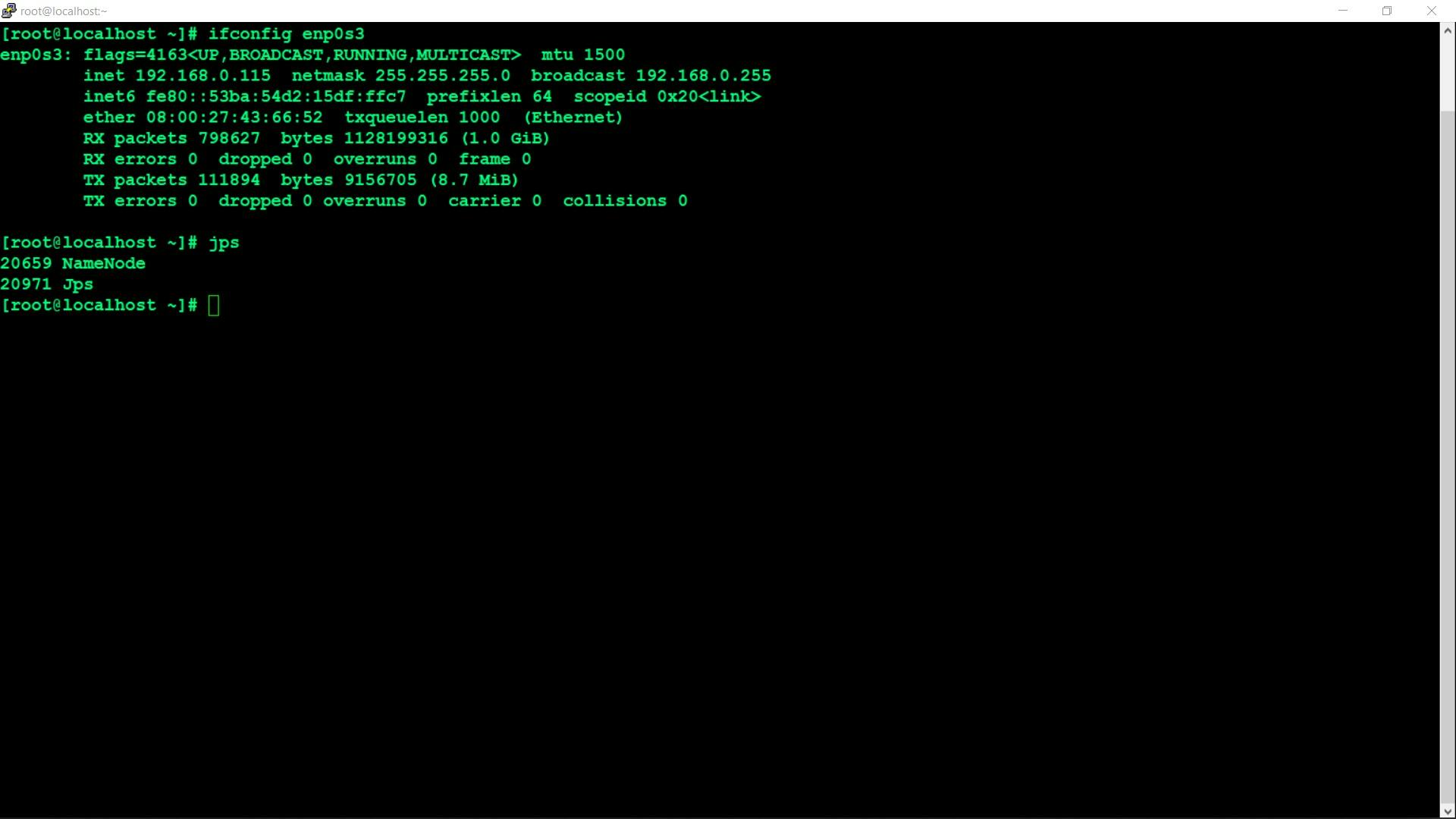
ansible-playbook datanode.yml
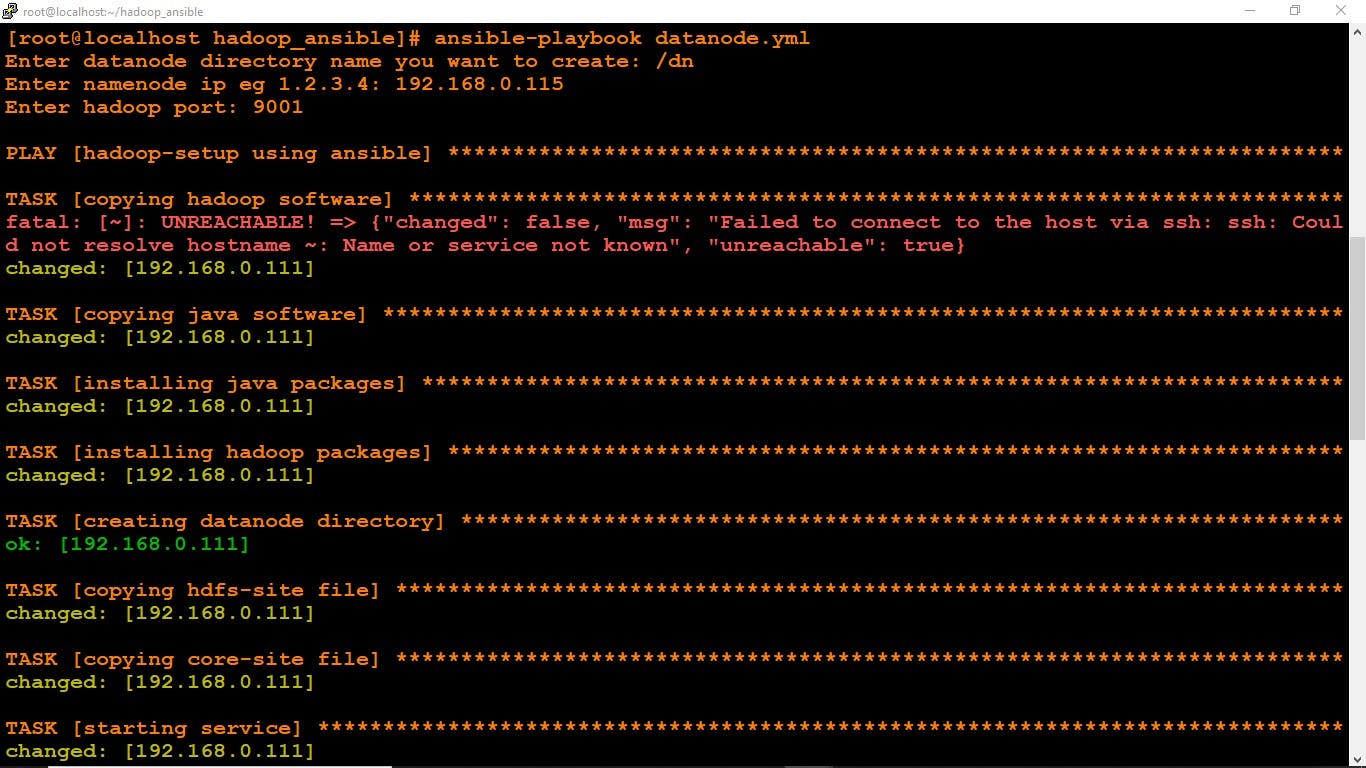
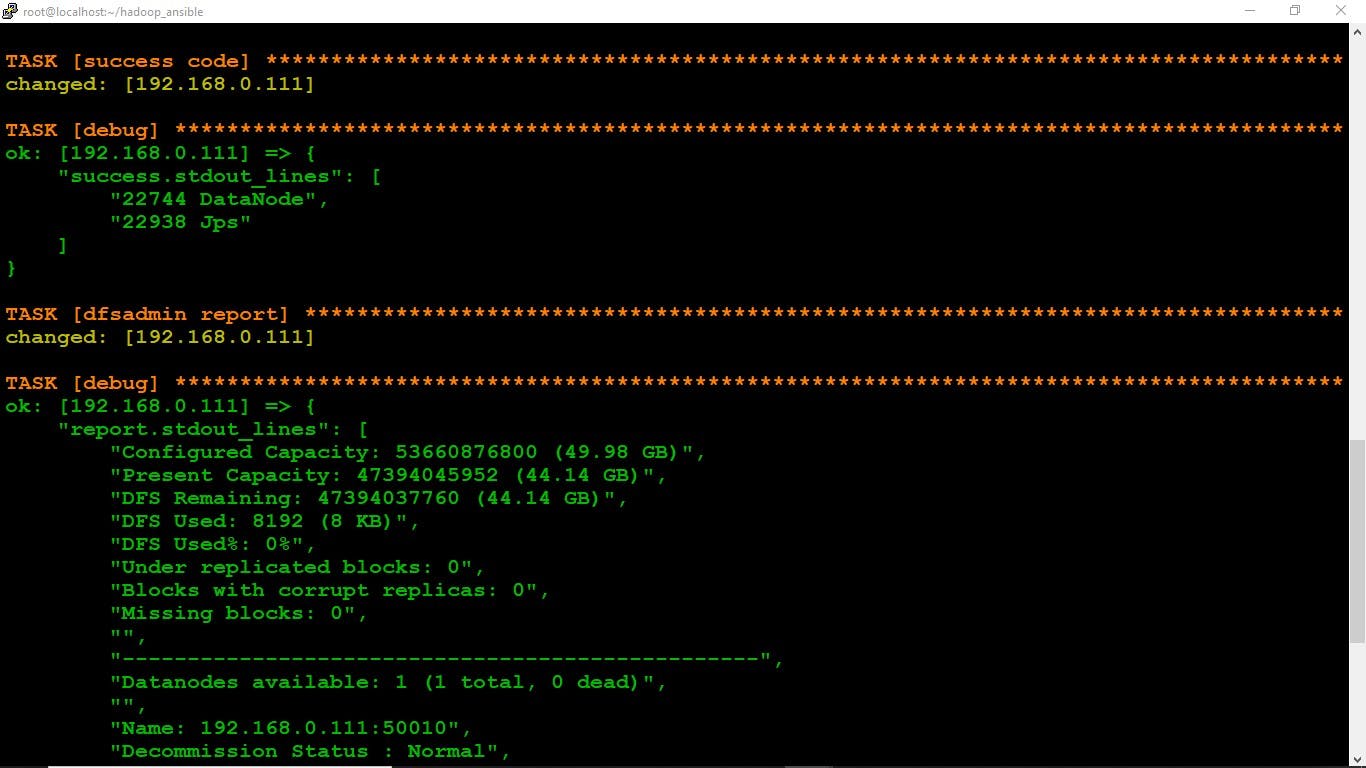
The Datanode is successfully configured
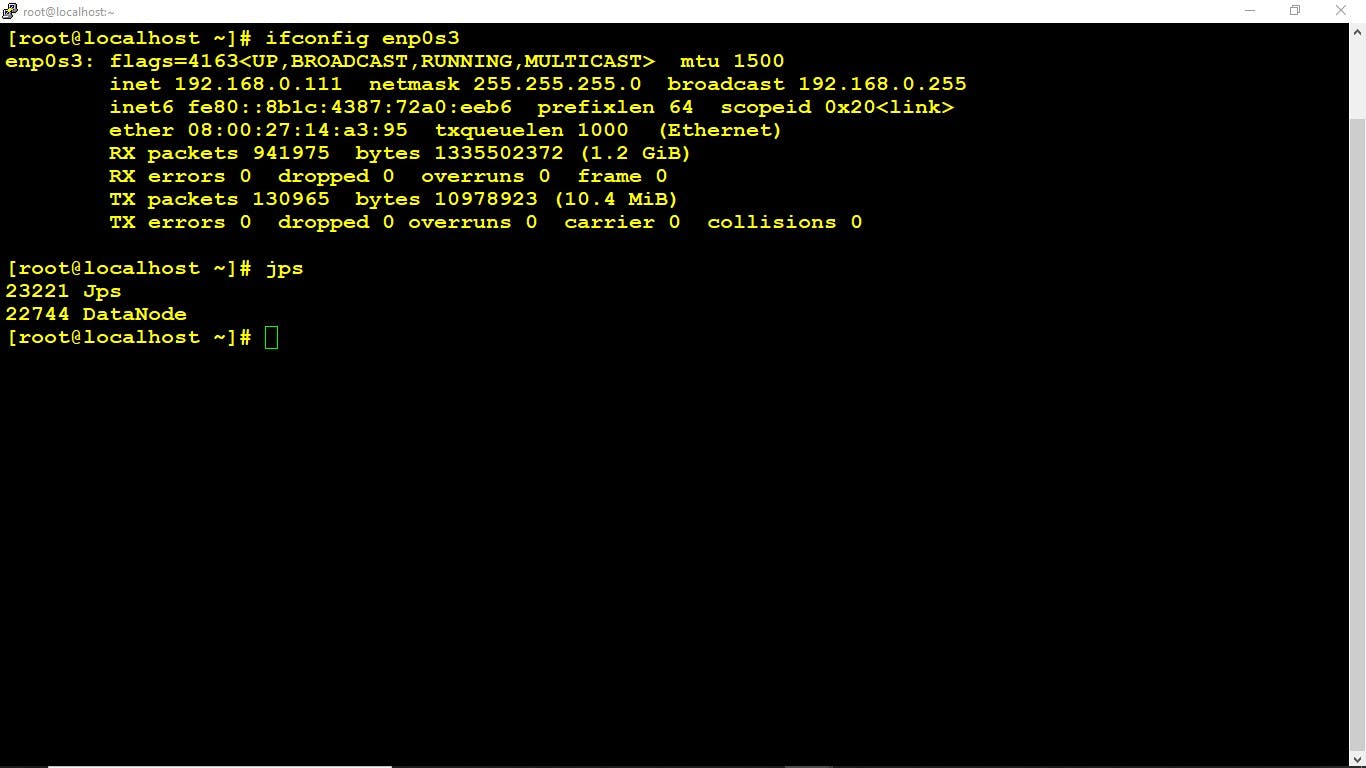
Conclusion:- The Hadoop is Configure automatically by Ansible, If you want to Configure Docker from Ansible then please refer to my Previous Article