
Compiler Structure


Prerequisite
To understand fully this post, you should know basic programming concepts like ( Conditionals, Loops, Variables .. etc). Also, you should know how to write simple programs.
Introduction
Compilers are the software systems that translate our programming languages into machine language. Machine language is the language that computers can understand. Machine language is not a human readable language. For that, programming languages have been made so we could write our programs more easily and share them with other developers.
compilers can translate from any language to any language not only machine language.The input language to the compilers are called source language. The output language from compilers are called target language.
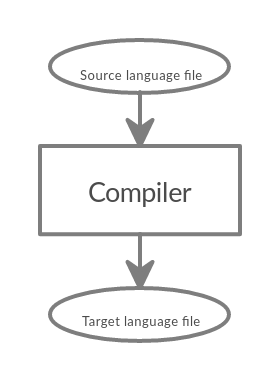
Language processors
A language processor is a software program designed or used to perform tasks such as processing program code to machine code.
There are two types of language processors :
- Translator : Takes a program code and translate it to machine code. Assembler and compiler are examples of translators
- Interpreter : Instead of producing a target program as a translation, the interpreter directly execute the operations in the source code.
The machine code is faster than the interpreter in producing the output. However, the interpreter is better in error diagnostics as it executes the source code statement by statement.
Compiler structure
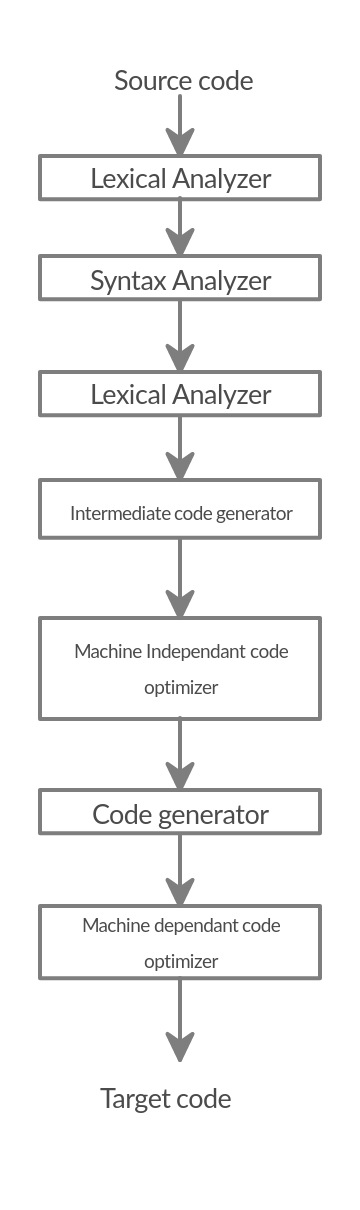
Lexical Analyzer
Lexical analysis is the first stage of a compiler. In this stage, The lexical analyzer takes the source code and transform it to some lexemes or tokens. Each token is composed of a token name and a token value.
// Token
< token name, token value >
Example
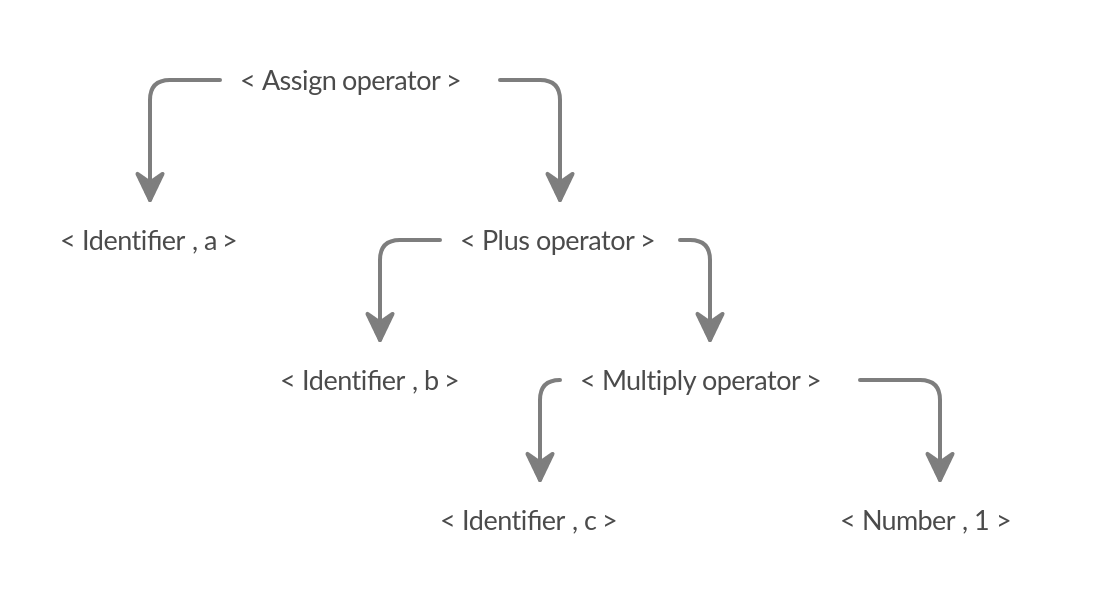
a = b + c * 1;
This line of code will produce tokens :
- < Identifier , a >
- < Assign operator >
- < Identifier , b >
- < Plus operator >
- < Identifier , c >
- < Multiply operator >
- < Number , 1 >
Note that, not all tokens have token value.
Syntax Analyzer
Syntax analyzer is the second stage of the compiler. It is also called the parser. The parser takes the tokens from the lexical analyzer and produces a syntax tree. The syntax tree is a typical representation in which each interior node is an operation and the children of the node are the arguments of the operation.
Example of a syntax tree
This tree is generated from the tokens in the previous example of lexical analysis.
Semantic Analyzer
Semantic Analyzer checks the source code for semantic consistency with the language definition. Semantic analyzer also gathers type information and stores it in the syntax table for Intermediate code generation. suppose we try to put a floating-pont number as an index to an array, the semantic analyzer will report an error from this situation. The input to semantic analyzer is the syntax tree generated by the parser. The output from the semantic analyzer is modified syntax tree.
Example
Suppose we have the same line of code we have from the previous example, and the identifiers all have a type of float. So in ( c * 1), we are trying to multiply a float and int ( 1 ). In this situation, the semantic analyzer will store in the syntax tree that 1 should be converted to float.
Intermediate code generator
The Intermediate code generator gets the syntax tree generated by the semantic analyzer, and outputs an Intermediate code. The goal of this stage is to apply the machine Independant code optimizations before translating to the target code.
Example
The Intermediate code generated for our line of code is :
t1 = inttofloat(1)
t2 = c * t1
t3 = b + t2
a = t3
Machine-Independant code optimizer
The optimizations in this stage run on the Intermediate code to enhance the generated target code. The optimizations must not slow down the compilation speed significantly. The optimizations target the increase in memory and time efficiency not just time.
Example
The Intermediate code generated in the previous example code be optimized to :
t1 = c * 1.0
a = b + t1
That optimization made us use only t1 instead of using t1, t2, and t3. so that enhanced the memory. Also instead of calling function inttofloat, we have used the floating-point number1.0 directly.
Code generator
The code generator maps the intermediate code to the target code. If the target language is assembly code then registers, and memory locations are used for the program identifiers.
Example
The generated assembly code from the optimized intermediate code from the previous stage is :
LDF R1, c
MULF R1, R1, #1.0
LDF R2, b
ADDF R3, R2, R1
STRF a, R3
- LDF : load float
- STRF : store float
- MULF : multiply float
- ADDF : add float
- All the Rx are registers
Machine dependant code optimizer
This stage exists when the target code is machine code. After generating the machine code from the previous stage, some optimizations relevant to the specific machine that the code runs on could be done. Like if we have a machine that have an xor operation in its hardware, so we apply this xor operation instead of decompose the xor to addition, subtraction, multiplication, and division operations. The optimizations in this stage could be done on one machine and couldn't on another so it is machine dependant.