Adaptive KV-Cache Quantization: How 'Don't Waste Bits' Cuts On-Device LLM Latency by 17%
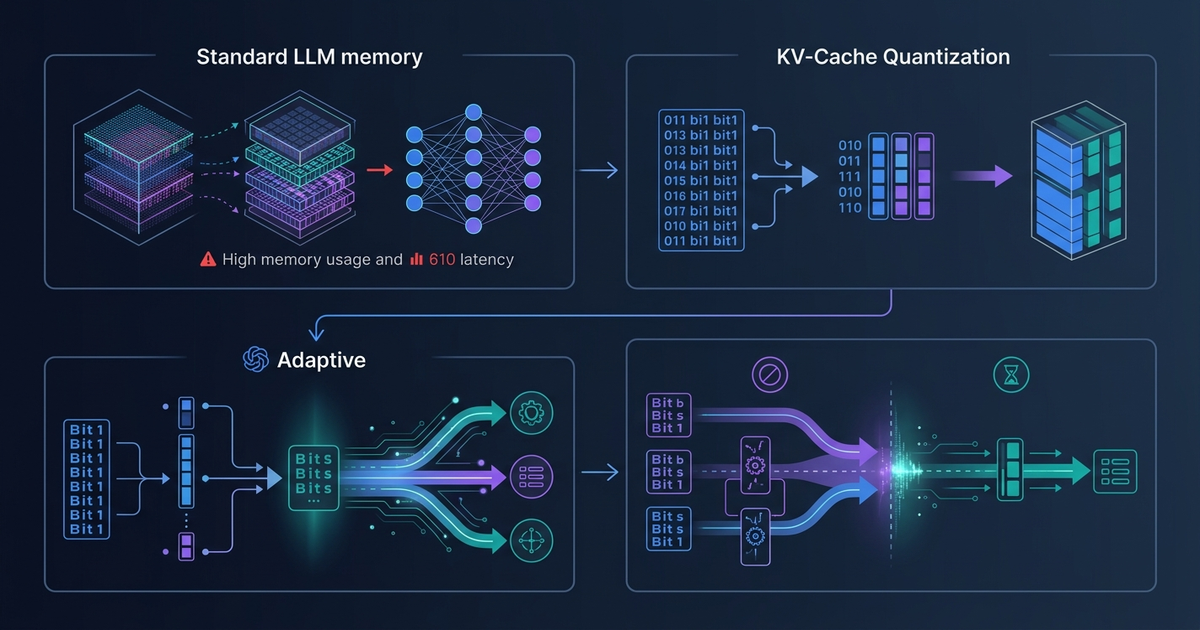
Running LLMs on-device means fighting two constraints simultaneously: memory and latency. The KV-cache — the buffer that stores past token representations so the model does not recompute them — is often the bottleneck on both fronts.
A paper publishe...
effloow.hashnode.dev7 min read