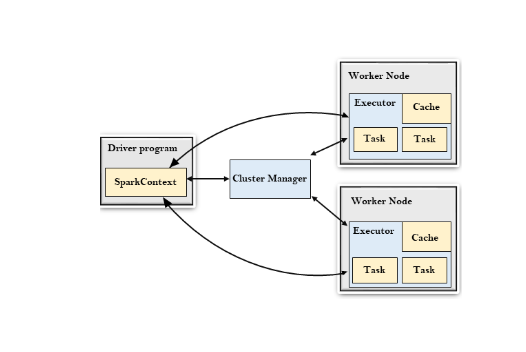
Apache Spark Architecture
Apache Spark’s architecture is a cornerstone of its ability to efficiently process large-scale data. It is designed around the concept of distributed computing, which enables it to process massive datasets quickly and reliably across a cluster of com...
bigdatageek.dev4 min read