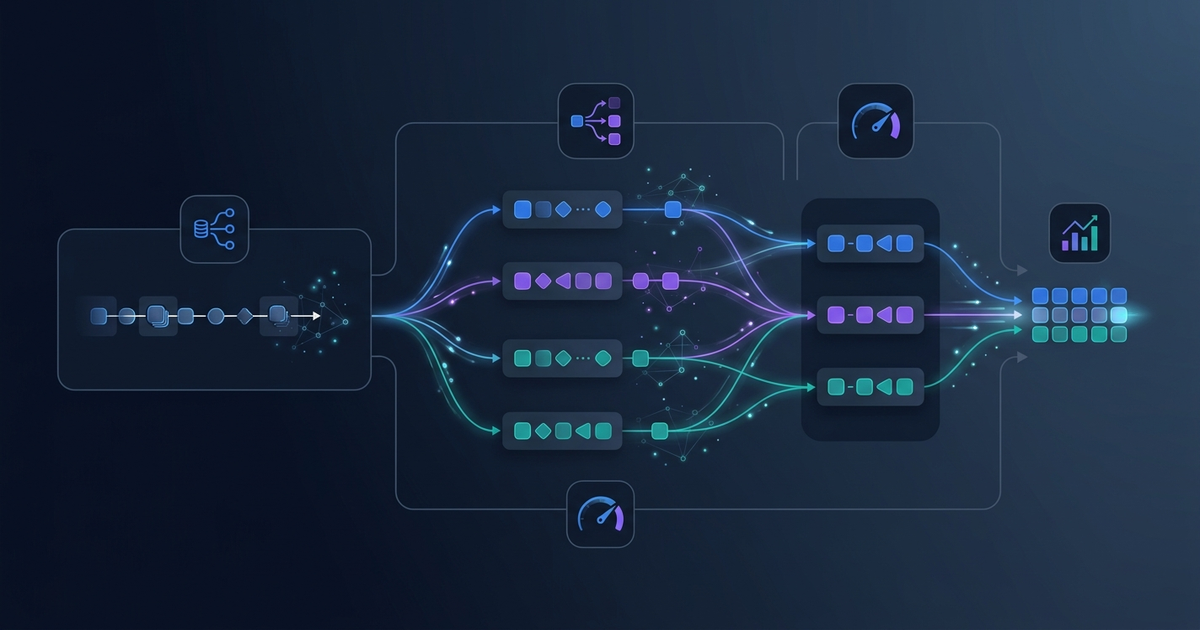
PARSE: Faster LLM Inference via Parallel Prefix Speculative Decoding
Speculative decoding became the standard inference speedup technique through 2024 and 2025. The idea: a small draft model generates a sequence of candidate tokens, and a larger target model verifies them in parallel — accepting the longest valid pref...
effloow.hashnode.dev5 min read