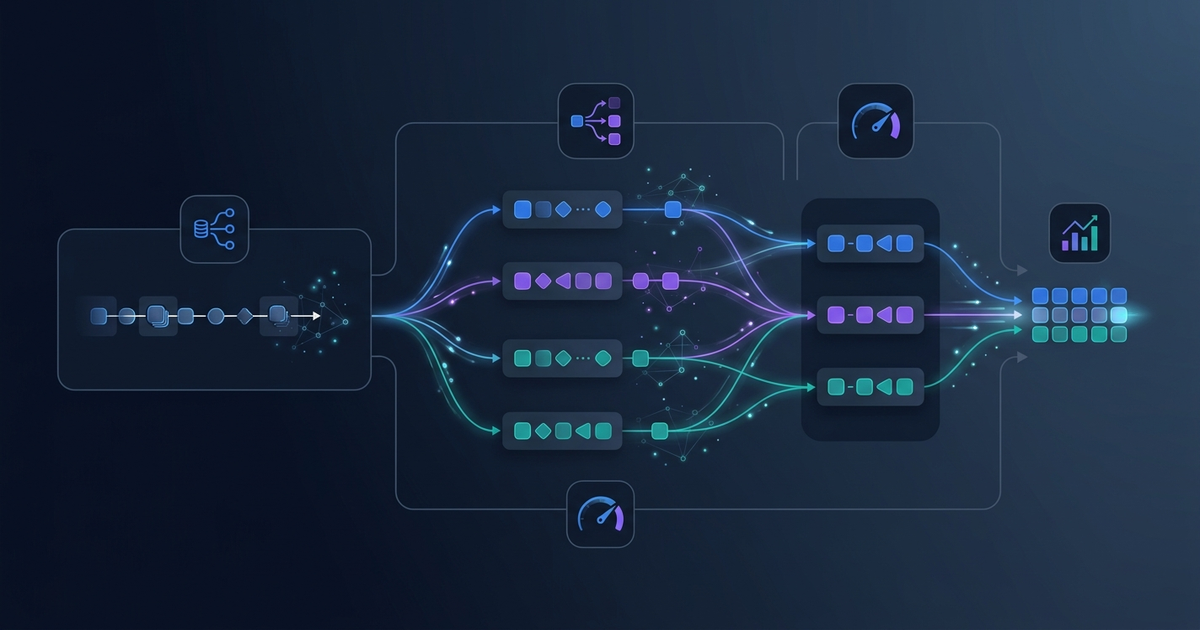
Continuous Speculative Decoding for Efficient Image Generation
Arxiv: https://arxiv.org/abs/2411.11925v1
PDF: https://arxiv.org/pdf/2411.11925v1.pdf
Authors: Shiming Xiang, Fei Li, Qi Yang, Kun Ding, Robert Zhang, Zili Wang
Published: 2024-11-18
Introduction: Enhancing Autoregressive Image Generation
Autoregres...