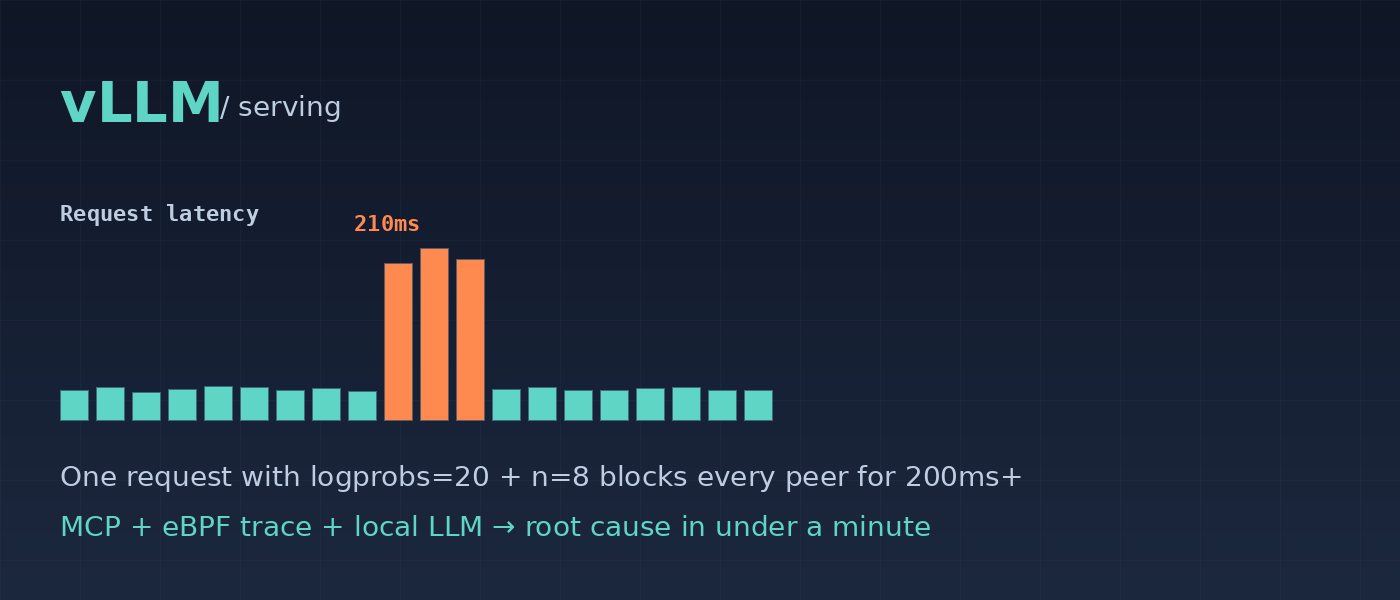
Catching a vLLM Latency Spike with eBPF and an Open-Weight LLM
TL;DR
A vLLM latency spike was debugged using a fully open source stack: eBPF kernel tracing + MiniMax M2.7 (open-weight model via Ollama) + MCP (open protocol). The AI autonomously called 4 tools, i
ingero.hashnode.dev7 min read