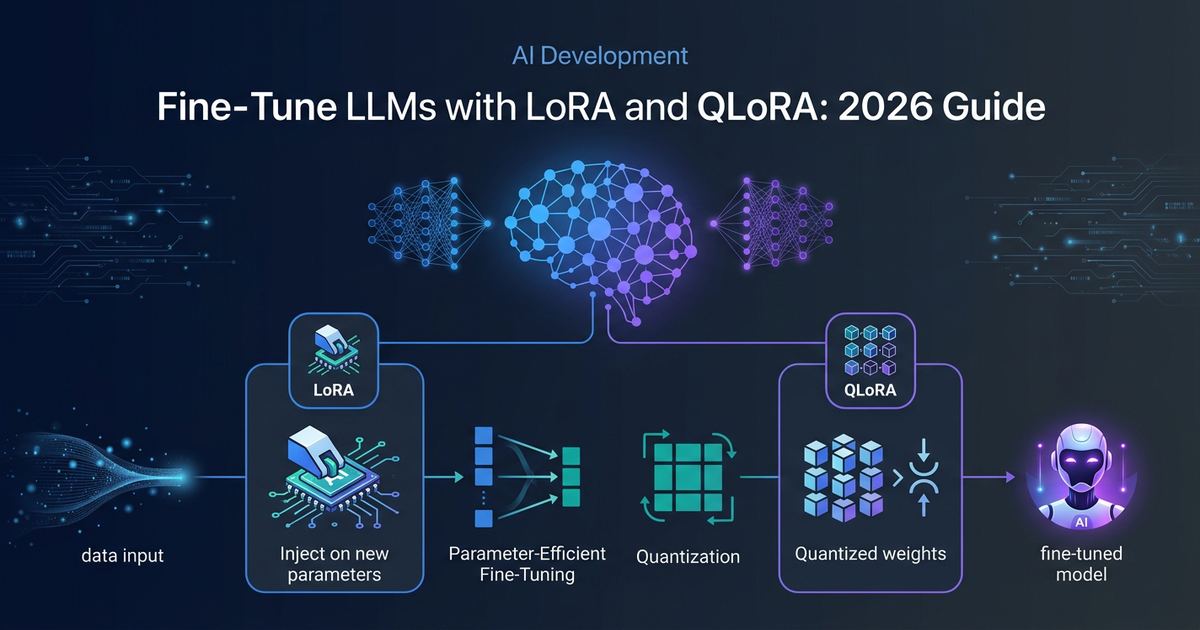
Fine-Tune LLMs with LoRA and QLoRA: 2026 Guide
Two years ago, fine-tuning a large language model required a rack of A100s, a machine learning team, and a five-figure cloud bill. In 2026, a single RTX 4070 Ti is enough to specialize a 7B model on your domain data — in an afternoon.
That shift happ...