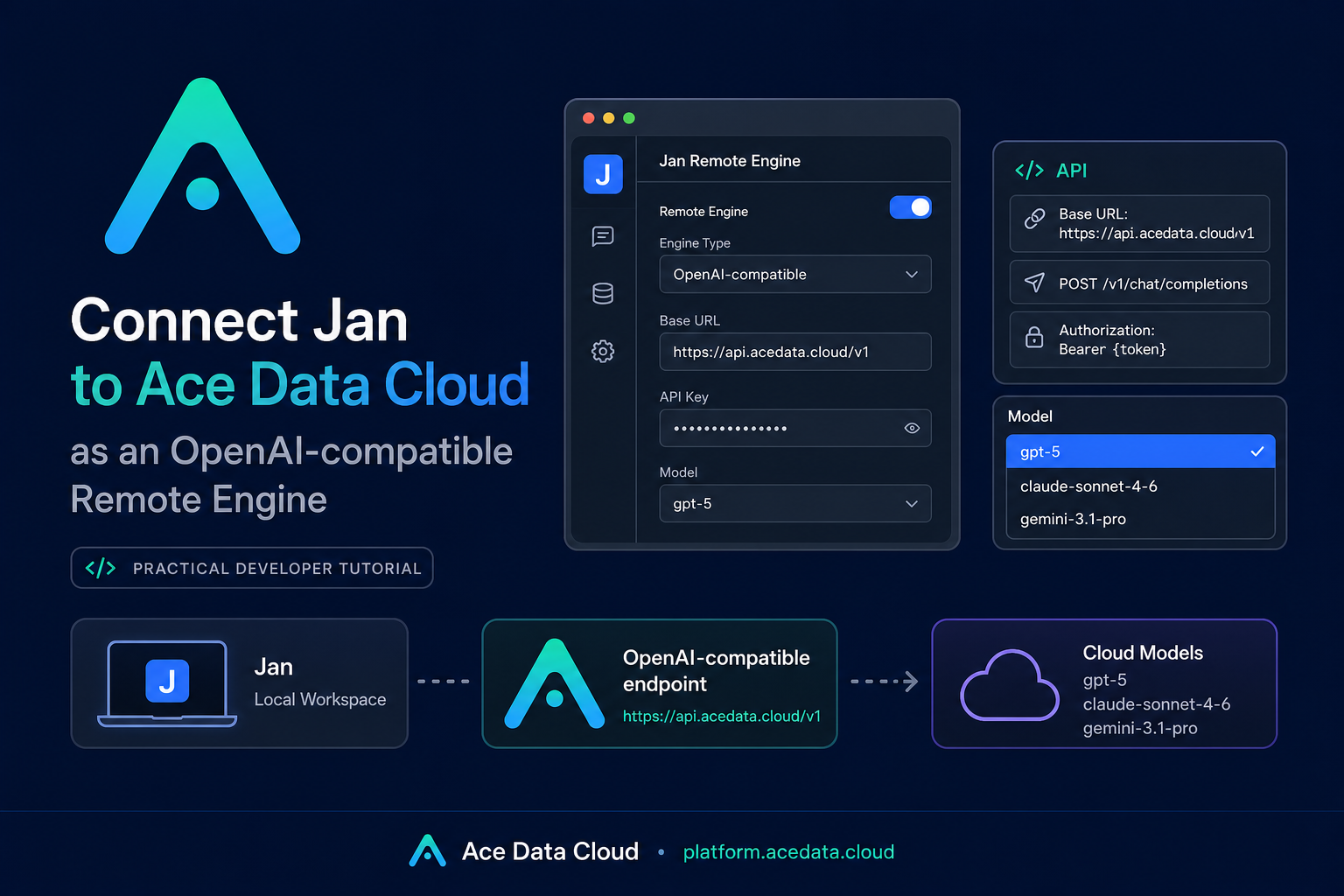
ADAce Data Cloudinacedatacloud.hashnode.dev·1d ago · 5 min readHow to Use Jan with Ace Data Cloud Remote ModelsIf you like using a local-first desktop AI client, but still need reliable access to stronger cloud models for harder work, Jan’s Remote Engine is a small configuration step that can make your setup m00
MCMaya Chenincreditrefresh.hashnode.dev·2d ago · 10 min readWhat Developers Should Know Before Their App Touches Credit Report DataA product manager asks for a feature that shows users their credit data. It reads like one more integration: get a token, call the endpoint, render the JSON. It is not. The moment a consumer credit re00
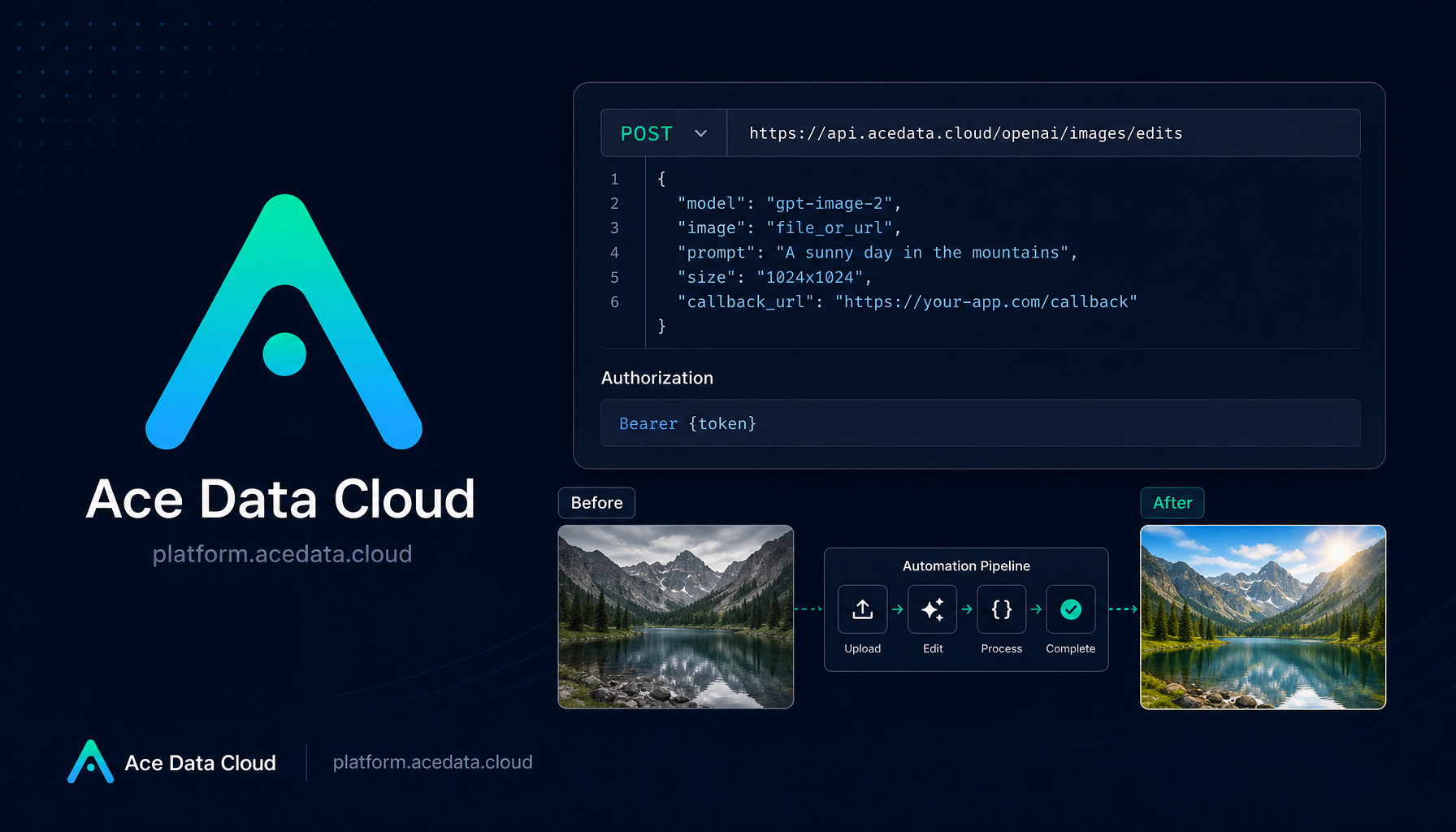
ADAce Data Cloudinacedatacloud.hashnode.dev·2d ago · 6 min readHow to Build a Practical Image Editing Workflow with GPT-Image-2 (Beginner's Guide)If you have ever tried to automate image edits, the hard part is usually not the model call itself — it is keeping the original structure intact while changing only the part you actually meant to chan00
DDietlyindietly.hashnode.dev·2d ago · 3 min readTaming Open Food Facts: building a fast, searchable nutrition databaseTaming Open Food Facts: building a fast, searchable nutrition database Every nutrition-app developer hits the same wall. Open Food Facts is a gift, millions of real, barcoded products, but it's crowds10
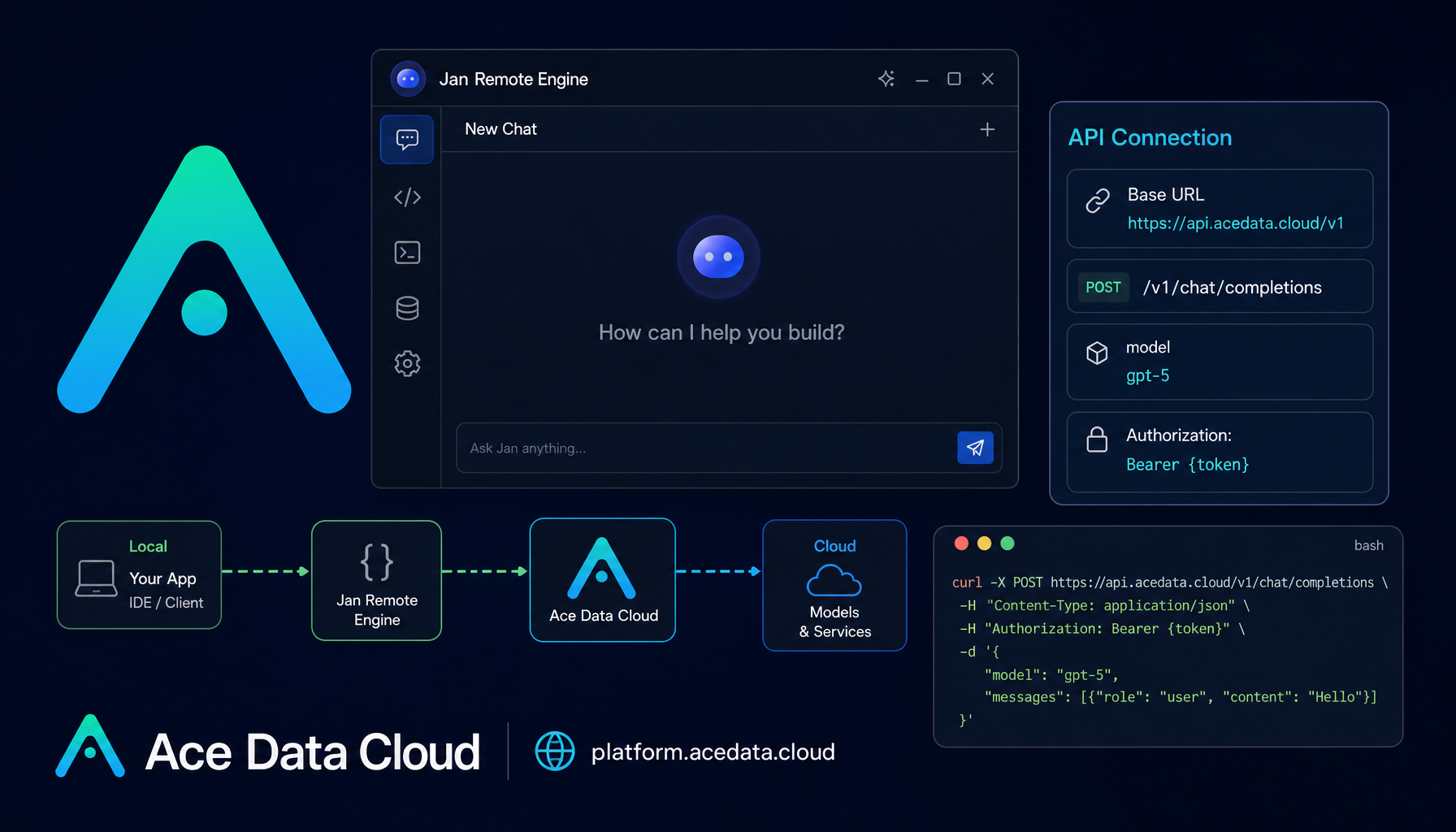
ADAce Data Cloudinacedatacloud.hashnode.dev·3d ago · 6 min readHow to Use Jan with Ace Data Cloud (Beginner's Guide)If you like running local models but still want a clean path to stronger cloud models when a task gets heavier, Jan gives you a practical middle ground: one desktop client, local and remote engines, a00
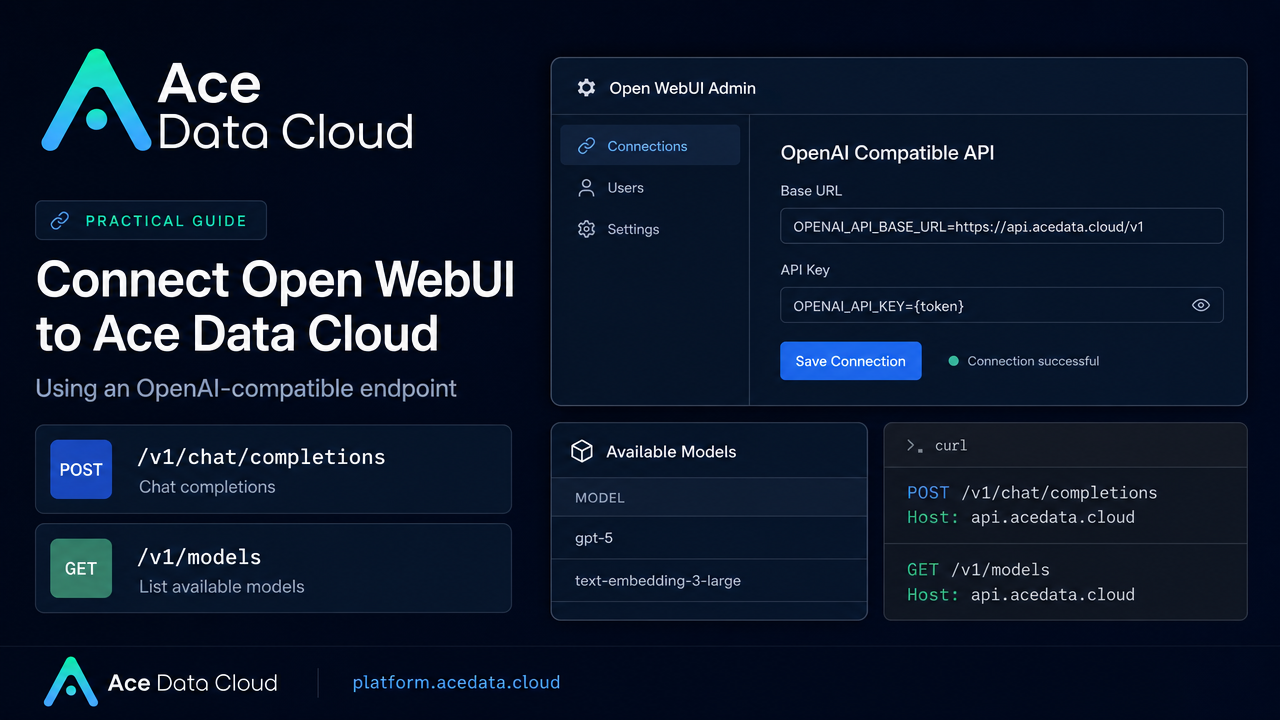
ADAce Data Cloudinacedatacloud.hashnode.dev·3d ago · 5 min readHow to Connect Open WebUI to an OpenAI-Compatible API (Beginner's Guide)If you have ever wanted a private, team-friendly chat UI without giving up access to multiple hosted model families, Open WebUI is a practical place to start: this guide shows how to point it at Ace D00
ADAce Data Cloudinacedatacloud.hashnode.dev·4d ago · 6 min readHow to Edit Images with GPT-Image-2 Using an API (Beginner's Guide)If you already have a generated image, product shot, poster, or UI mockup, the next hard part is usually not creating a new image from scratch — it is changing one thing without breaking the rest. Th00
ADAce Data Cloudinacedatacloud.hashnode.dev·4d ago · 5 min readHow to Retrieve Async OpenAI Image Tasks with Ace Data CloudIf you generate or edit images through an API, you eventually hit the same practical problem: some requests take longer than your app wants to wait, but you still need a reliable way to find the resul00
ADAce Data Cloudinacedatacloud.hashnode.dev·5d ago · 5 min readHow to Connect Open WebUI to an OpenAI-Compatible Model GatewayIf you already like Open WebUI as a self-hosted AI workspace, the next question is usually practical: how do you connect it to a broader set of hosted models without rewriting your setup? Open WebUI 00
EIEugeniya Ivanovainpublora.hashnode.dev·5d ago · 5 min readGive Your AI Agent the Power to Post: Scheduling Social Media from an LLM via MCPLLM agents are good at writing content. Publishing it is still surprisingly awkward. Every social network has its own OAuth flow, API quirks, rate limits, and media requirements. Supporting one platfo10