SNShakiran Nannyombiinshakiran.hashnode.dev·Jul 21 · 4 min readBuilding a Hackathon from the Ground UpOn July 18, 2026, we hosted the Build with Gemma Hackathon at Makerere University, bringing together over 30 students and developers to build AI-powered solutions using Google's open Gemma models. The00
IKIvan Klawdinblog.thecgaigroup.com·Jun 6 · 16 min readA 12B You Can Run on a Laptop: Local Inference Grows UpA 12B You Can Run on a Laptop: Local Inference Grows Up For two years the local-AI argument lost on the same sentence every time: "It's impressive that it runs on your laptop, but you wouldn't actuall00
HHemaNinhema-sdet.hashnode.dev·May 19 · 14 min readFrom Test Cases to Prompts: How I Built an AI Receipt Scanner as a Quality Engineer with No Dev BackgroundWho This Article Is For If you are a QA engineer, SDET, or anyone from a non-development background who has been watching the AI wave from the sidelines thinking "this isn't for me" — this article is 00
PYPhaneesh Yalavarthiinphaneesh.hashnode.dev·May 11 · 1 min readLocal AI: Running Gemma 4 with llama.cpp and DockerIntroduction In the rapidly evolving landscape of Artificial Intelligence, the ability to run Large Language Models (LLMs) locally has become a game-changer for developers and researchers alike. Wheth00
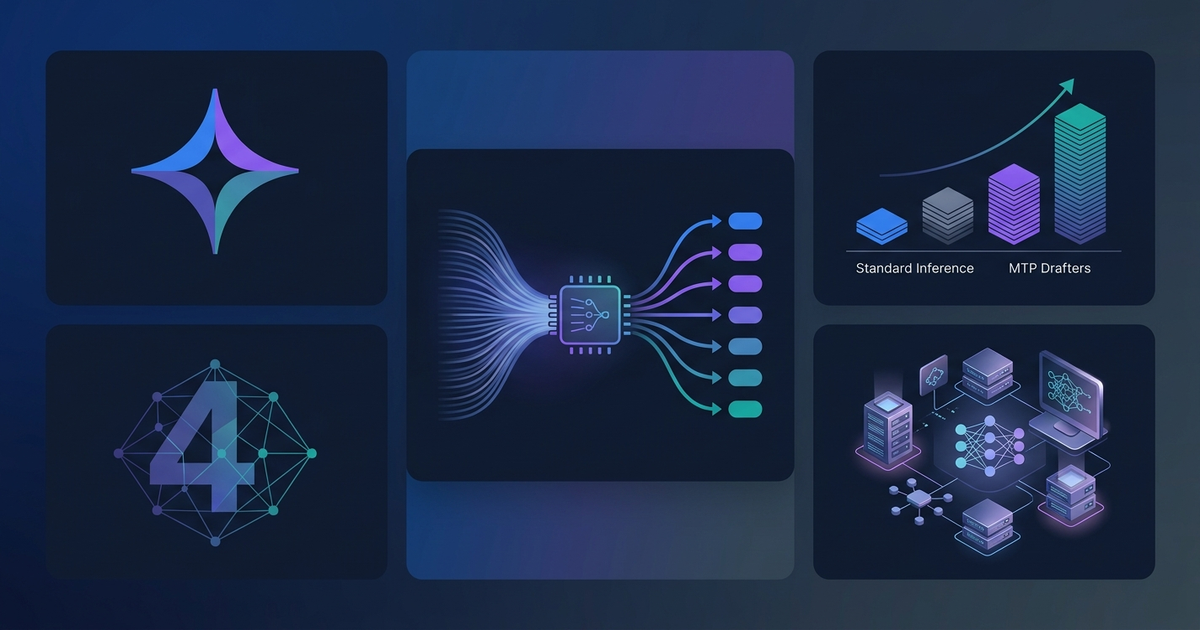
JKJangwook Kimineffloow.hashnode.dev·May 9 · 6 min readGemma 4 MTP Drafters: How Multi-Token Prediction Delivers 2x+ Faster Local InferenceOn May 5, 2026, Google released Multi-Token Prediction (MTP) drafters for the Gemma 4 family. The headline claim — up to 3x inference speedup — is technically accurate on specific hardware. The more realistic number for most developer setups is 1.7x ...00
강강문규indevsnack.hashnode.dev·May 6 · 8 min readGemma 4 MTP Drafter on DGX Spark: 2.89x Speedup for Dense 31B — No Quality LossAn 870 MB drafter model turned Dense 31B from 6.5 → 18.8 tok/s. No model swap, no training, no quality degradation. If you have a DGX Spark, there's no reason not to use this. Key Results Model Fra00
APAnkita Patilinblog.ankitapatil.dev·May 4 · 3 min readMoving the Brains to the Metal: My Local AI Setup with Gemma 4Building for the web in 2026 means being an AI orchestrator. Most devs are just API consumers, but if you want to understand the stack, you move the intelligence to the metal. I recently migrated my w00
AKAnup Karanjkarinwowhow.hashnode.dev·May 2 · 8 min readTop 5 AI Tools Worth Trying in April 2026 (That Aren't ChatGPT or Claude)The interesting AI tool developments in April 2026 are not happening at the general-purpose chatbot layer. ChatGPT and Claude are both strong and well-documented. The tools below sit in a different category: they are specialized, they do specific thi...00
AKAnup Karanjkarinwowhow.hashnode.dev·May 2 · 10 min readGoogle Gemma 4: Apache 2.0 Open Models That Run on Your Laptop (2026)Google DeepMind released Gemma 4 on April 2, 2026, and two things make it immediately significant: Apache 2.0 licensing and hardware efficiency that no competitor at this capability level matches. Gemma 4’s 31B Dense model ranks third globally among ...00
JKJangwook Kimineffloow.hashnode.dev·May 1 · 10 min readGemma 4 26B vs 31B: Which Model to Run LocallyGemma 4 26B vs 31B: Which Model to Run Locally with Ollama If you followed our Gemma 4 Local Setup Guide, you already have Ollama running and know the four model sizes exist. But once you're past the basics, a real question stays open: between the 26...00