How We Made 100M Vector Indexing in 20 Minutes Possible on PostgreSQL
1. Introduction
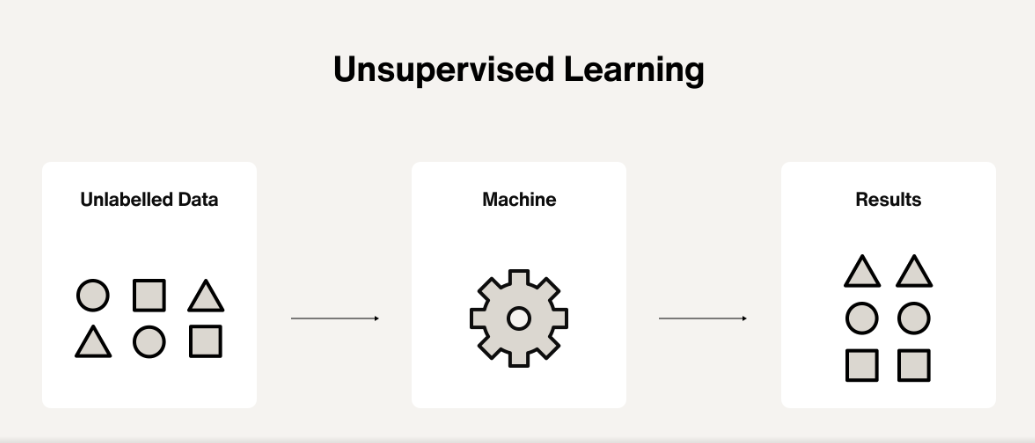
In the past few months, we’ve heard consistent feedback from users and partners: while our goal of providing a scalable, high-performance alternative to pgvector is well-received, index build time and memory usage remain major concern...